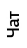Давно интересовал вопрос о выборе наиболее близкой к реальным данным функции распределения если подходят несколько (в смысле не отвергается гипотеза о принадлежности опытной функции распределения к гипотетической). Сформировалось следующая методика:
0. Имеется выборка

большого объёма, например 1000, и по ней сделано предположение, что ГС может быть распределена как по
$")
, так и по
$")
. Какую из гипотез следует принять? В литературе по матстатистике ответа не нашёл, поэтому предлагаю следующий способ:
1. Из
случайным образом извлекается безповторная выборка меньшего объёма

, пусть 100, и по ней находятся параметры для
и
. Эта выборка затем возвращается в
.
2. Из
случайным образом извлекается следующая безповторная выборка объёма
и для неё находится величина суммы квадратов невязок (

) для
и
. Эта выборка затем также возвращается в
.
3. Пункт 2). повторяем

раз.
4. Использование полученных результатов. Пусть в

случаях из
}<CKH_{F_2(x)}$")
, тогда с вероятностью

выбирается функция
.
Я понятно изложил? Что вы на это скажете?