шум 20%, то есть ни одна модель не может дать акураси больше 80% ТЕОРЕТИЧЕСКИ, а если вы обучаете до 100% на лёрне, это автоматически значит что модель выучила этот 20%й шум и будет ХУЖЕ
> Кнн — не обучается, его модель — сам датасет, ... то есть переобучение
У вас с логикой все в порядке?
"Переобучение" — термин, слово, он не про конкретный тип процесса вычисления параметров, а про сложность модели, то есть количество параметров, не про итерации. Для Кнн эти параметры - компоненты векторов самого датасета, как есть, а инференс — вычисление ближайшего по близости векторов к классифицируемому. Сложность для Кнн обратно пропорциональна к(чем меньше к тем выше сложность). Ваше смущение про то что нет "обучения" но есть "переобучение", довольно наивно.
Медитируем на:
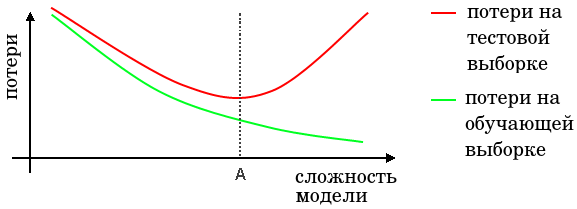
Цитата:
Поэтому формулировка "не может обучится до 100%" - это мягко говоря глупость. Это все равно, что сказать, что нет таких весов, чтобы решить систему линейных неравенств.
Никто не говорит про то что перцептрон или какой либо достаточно ёмкий алгоритм МЛ не даст 100% на лёрне, речь же не об этом, а о том что при этом будет не оптимальная модель на тесте, на данных вне обучающей выборки. Я вам привёл конкретный пример с Кнн который это иллюстрирует, если поставить вместо Кнн млп, перцептрон или лес, будет, полагаю близкая картина.
а если вы обучаете до 100% на лёрне, это автоматически значит что модель выучила этот 20%й шум и будет ХУЖЕ
Вообще не значит. Никто не запрещает взять алгоритм "для точек из обучающей выборки использовать knn-1, для остальных что-то другое".
Вообще говоря да, если знать с какой выборки поступают данные)))
Отлично, тогда вы наверно сможете описать некую процедуру, которая определит переобучен алгоритм или нет. Только нужно договорится, что мы называем решением. А то мы и тут это слово понимаем по разному. Решение это по определению - 100% решение на обучающей выборке. Все остальное, это не до конца сходящийся процесс. Так я вот не могу в толк взять, в каком момент это не до конца сходящийся процесс может оказаться стабильнее по точности прогноза, чем окончательно сошедшийся.
Да нет же, именно если будет 100% на обучении, то будет вероятней всего переобученная модель, если ест шум. Процедура — я вам код предоставил с графиками, постепенно нашариваем(или уменьшаем) сложность модели, ловим момент где экстремум на тестовой выборке. Вам же ссылку на авторитетный источник проставили.
https://deepmachinelearning.ru/docs/Mac ... derfitting "Схождение" тут не причем, сложность это не про итерации, а про параметры, в случае нейросетей это количество весов "Схождение" — выход на плато, кривой ошибки, в случае итеративных методов, Кнн или линейная регресия например не сходятся, в этом смысле, там нет иттераций. У вас собственные термины и критерии, предлагаю придерживаться общепринятых.





 < L(A_2, T)$")
$")


 > L(A_2, D)$")


{kind=link}