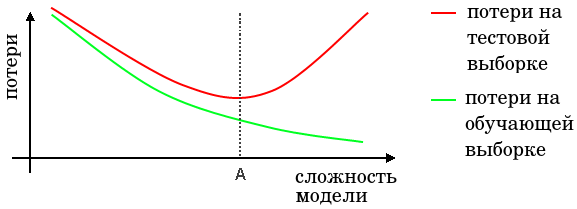
Но тут важно различать, как была найдена "точка стагнации". Её причиной может быть "не связанные" примеры, "противоречивые" примеры, недостаточная разрешающая способность сетчатки и недостаточная емкость среднего слоя (если число нейронов меньше числа примеров в обучающей выборки). Если последние две причины можно устранить (хотя практически это вычислительно затратно), то различие между "не связанными" и "противоречивыми" примерами формально установить сложнее.
Пример полностью противоречивого примера я уже давал
Цитата:
У нас 2 бита на входе, и 1 бит на выходе. Если комбинация помечена как 01 как класс 0, и точно такая же комбинация помечена 01 помечена как класс 1 - примеры в выборке противоречивы.
А вот пример, частично противоречивого примера, описывается сложнее и хуже понятен, но формально это то что я тоже уже приводил
Цитата:
не должно существовать никакой подпоследовательности стимулов, содержащей по меньшей мере по одному стимулу каждого класса, которая приводила бы к одинаковому коэффициенту смещения для каждого А-элемента в множестве А-элементов, реагирующих на эту подпоследовательность.
Коэффициентом смещения для А-элемента Ф. Розенблатт называл отношение n_i^+/n_i^- числа стимулов в обучающей выборке, которые относятся к одному классу, и возбуждают данный А — элемент, к числу стимулов, относящихся к другому классу, но также возбуждающие этот же А-элемент. Нарушение второго условия делает отношение n_i^+/n_i^- постоянным для А-элементов, реагирующих на стимулы из такой определённой подпоследовательности появления стимулов на входах перцептрона.
если провести кластеризацию, то такие частично противоречивые примеры, будут на границе разных классов. Я как раз сейчас занимаюсь экспериментами в этом, для чего очень репрезентативна задача MNIST Fashion (различение пиктограмм одежды). И вот эти примеры на границы предположительно все же могут дать вклад в качество прогноза.
Но если исключить такие частично противоречивые примеры, то останутся не связанные. Формально их видимо можно определить в терминах кластеризации, это те примеры у которых очень грязная чистота окрестностей. Степень грязности можно выбирать.
-- Сб ноя 01, 2025 00:16:21 --Пока открыл 4.2. Не очень понял, чем это отличается от стандартных сейчас нейросетей, если в качестве активации взять функцию Хевисайда. Можете это как-то кратко описать?
Первый слой S-A - это не полносвязный слой, с фиксированными весами +1 или -1, или 0 если связи нет. В остальном этот слой стандартный и не обучаемый. Но это как раз тот слой который при достаточно большом числе А-элементов обеспечивает отображение нелиниейной задачи в линейную. Слой A-R - это линейный классификатор.
-- Сб ноя 01, 2025 00:17:29 --Вообще, для этой целей темы - задержка важна, или можно её игнорировать?
Нет, не важна .. просто у Розенблатта есть рекурентные сети, и поэтому он вводит задержку.
-- Сб ноя 01, 2025 00:18:58 --Что такое "стимул" - набор признаков? набор признаков + метка? что-то еще?)?
один пример любой выборки, который состоит из всех бинарных признаков.
-- Сб ноя 01, 2025 00:20:32 --Что такое "эксперимент" - датасет?
нет, в нашем контексте - это обучение + проверка на тесте
-- Сб ноя 01, 2025 00:21:36 --Что такое "сенсорные элементы" в случае произвольной модели?
Это входы системы, принимающие бинарные признаки одного примера.
-- Сб ноя 01, 2025 00:23:49 --И, наконец, что такое "полное отличие"?
Расположение (направление их в) бинарных признаков, описывающих объект совсем в других входах перцептрона (сенсорных элементах)

 + \operatorname{Acc}(A, \overline Y) = 1/2$")
 > \operatorname{Acc}(A', Y)$")
 < \operatorname{Acc}(A', Y)$")

$")
$")

 = 0$")

![$[0, 100]$](https://dxdy.ru/math/0e2109da05f9d8dc33b622fc1001a3c182.png "$[0, 100]$")
$")
 = \Theta(\theta(S(\vec x) \cdot A - \vec a) \cdot R)$")







 = 0$")

 = 1$")


 = 2 \theta(x) - 1$")