Дело в том, что современные суперкомпьютеры пока ещё всё-таки не могут заменить этап "придумывания алгоритма".
Прежде чем применить суперкомпьютер, надо написать хорошую программу, а для этого надо придумать хороший алгоритм.
Если, скажем, в данной задаче Зиммерманна, сунуть на кластер тупой перебор всех комбинаций, то, нверное, и кластер будет бессилен, например, уже для

.
Вот Кнут придумал некий алгоритм. Однако неясно, насколько он пригоден для кластера, можно ли из него сделать то самое распараллеливание, о котором все говорят, когда речь заходит о кластере.
-- Пт дек 10, 2010 14:41:18 --Цитата:
для кластера программа нужна не абы какая, а написанная специальным образом, чтобы это самое распараллеливание происходило.
Не обязательно. В конкурсах такого вида, когда есть набор независимых задач, можно каждому компьютеру из кластера задать поиск для другого "n". Это тоже распараллеливание.
Речь идёт не о таком распараллеливании, как поиск для различных

.
Распраллеливание имеется в виду в решении задачи для одного конкретного
.
И на том форуме однозначно было сказано, что для кластера нужна специальная программа.
-- Пт дек 10, 2010 14:48:02 --Цитата:
когда я говорил про автоматическое распаралеливание, я имел в виду только то, что программу, написанную, так сказать, как mpi-aware, планировщик разбрасывает...
Цитата:
мы на это и пытаемся обратить твоё внимание: программу изначально надо писать как "mpi-aware"
Кроме того, как показывает опыт решения задачи, эти задачи для разных
не являются совсем независимыми. Вполне можно засунуть в кластер алгоритм наращивания последовательностей; собирая данные о последовательностях для разных
с различных узлов, центральный процессор будет выполнять наращивание этих последовательностей, что тоже даёт очень неплохие результаты.
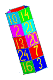
 , найденную мной по программе, присланной мне svb. Я её опробовала, она прекрасно работает (по крайней мере, для тех
, найденную мной по программе, присланной мне svb. Я её опробовала, она прекрасно работает (по крайней мере, для тех 
 на бесконечности.
на бесконечности. и для
и для  (первые результаты, бросившиеся в глаза: хотел уточнить сегодня остальные, но Вы результаты "потерли") были вчера-позавчера приведены результаты, которые хуже для максимальных раскладок, приводящих к тождественной последовательности, так что не надо сказок. Ведь речь идет об алгоритме, который ищет не менее одной
(первые результаты, бросившиеся в глаза: хотел уточнить сегодня остальные, но Вы результаты "потерли") были вчера-позавчера приведены результаты, которые хуже для максимальных раскладок, приводящих к тождественной последовательности, так что не надо сказок. Ведь речь идет об алгоритме, который ищет не менее одной 
 на моем компьютере работает примерно 4 сек, т.е. основное время сжирают проверки последовательностей. Я не раскрою никакого секрета, если сообщу, что от любой последовательности можно двигаться вниз по единственному пути и вверх по нескольким (от 0 до
на моем компьютере работает примерно 4 сек, т.е. основное время сжирают проверки последовательностей. Я не раскрою никакого секрета, если сообщу, что от любой последовательности можно двигаться вниз по единственному пути и вверх по нескольким (от 0 до  ) путям. Т.е. все последовательности организуются в виде дерева. Обход дерева многократно описан в литературе и тоже не представляет секрета. Для данной задачи этот обход достаточно легко оптимизируется, но ... уже для
) путям. Т.е. все последовательности организуются в виде дерева. Обход дерева многократно описан в литературе и тоже не представляет секрета. Для данной задачи этот обход достаточно легко оптимизируется, но ... уже для  ждать нужно очень долго, поэтому меня заинтриговали сообщения dvorkin_sacha о максимальных путях для
ждать нужно очень долго, поэтому меня заинтриговали сообщения dvorkin_sacha о максимальных путях для  . То, что он рассматривает в качестве начальной последовательности упорядоченный набор, не имеет особого значения, т.к. именно они основные кандидаты на рекордсмены. Конечно, возможно он и блефует, но, если это не так, то снимаю шляпу перед ним даже в случае, если это не поможет ему для
. То, что он рассматривает в качестве начальной последовательности упорядоченный набор, не имеет особого значения, т.к. именно они основные кандидаты на рекордсмены. Конечно, возможно он и блефует, но, если это не так, то снимаю шляпу перед ним даже в случае, если это не поможет ему для  . Об остальном я пока умолчу (хотя пока и говорить не о чем) до окончания конкурса. Кстати, соревнование даст пищу для оценки нижней границы - уже сейчас видно, что показатель при
. Об остальном я пока умолчу (хотя пока и говорить не о чем) до окончания конкурса. Кстати, соревнование даст пищу для оценки нижней границы - уже сейчас видно, что показатель при 