26/05/12
1918
приходит весна?
|
Последний раз редактировалось B@R5uk 17.04.2025, 01:55, всего редактировалось 1 раз.
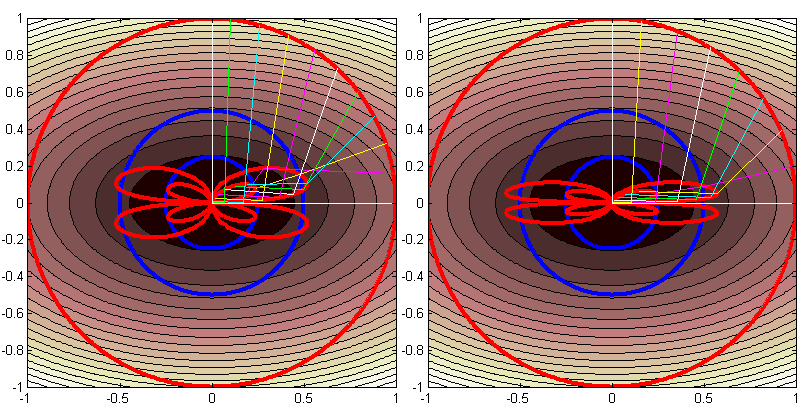
Но тут вопрос - а как выбрать этот множитель? Если нет никакой информации насчёт функции, то таки надо делать хотя бы неполную оптимизацию вдоль выбранного направления. Ну да, стратегии наискорейшего спуска и минимального градиента выбирают множитель за нас. Я тут попытался проанализировать, что в них происходит. Опять же на самой простой задаче: Квадратичная функция с минимумом в нуле:    Если потребовать минимум функции вдоль направления спуска (стратегия наискорейшего спуска, Steepest Descent) и проварьировать по параметру, то придём к формулам:   Если же потребовать минимум модуля (или, что более удобно квадрата модуля) градиента (стратегия минимального градиента, Minimum Gradient), то получится так:   Очевидно, оператор шага S в обоих стратегиях не является линейным (является дробно-рациональным?): =x-\frac{x^TA^2x}{x^TA^3x}Ax,\qquad\qquad S_{MG}\bigl(x\bigr)=x-\frac{x^TA^3x}{x^TA^4x}Ax$$") Пока не очень представляю, что с этим делать аналитически, поэтому попробовал промоделировать. Составил программку для двумерного случая с диагональной матрицей и задал начальное множество точек на единичной окружности и посмотрел, куда они отображаются обоими стратегиями (а так же, для сравнения, методом с оптимальным фиксированным шагом, выбранным исходя из априорного знания о квадратичной формы). Получилась следующая картинка: Сразу говорю, на картинке нарисована неправда: проекции окружности после первой итерации перевёрнуты по вертикали. Я это сделал, чтобы продемонстрировать, что существует выделенное направление, векторы вдоль которого при применении оператора шага S, во-первых укорачиваются медленно, а во-вторых не меняют своего направления (с учётом смены знака по координате y). Траектории, для них — это (жёлтая) линия, вторая против часовой стрелки от горизонтальной белой на левом графике и первая, розовая — на втором. Левый график соответствует стратегии максимального спуска, правый — минимального градиента. Синими окружностями помечены точки, в которые отображается исходная единичная окружность стратегией с фиксированным шагом. Получаются окружности, а не эллипсы, потому что шаг выбран оптимальным, а это даёт одинаковые собственные числа для оператора S, соответствующие минимальному и максимальному собственным числам матрицы A квадратичной формы. Поскольку задача двумерная, других чисел быть не может. Поскольку я перевернул результат первой итерации по вертикали, траектории, отмеченные разноцветными тонкими линиями, перестали быть ортогональными линиям уровня целевой функции, если первую итерацию перевернуть назад, то будет всё нормально. Видно, что методы наискорейшего спуска и минимального градиента в самом худшем случае чуть-чуть хуже метода с фиксированным градиентом с оптимально подобранным шагом. По крайней мере в двумерии. Так же, если очень присмотреться, то можно заметить, что векторы в процессе итераций прижимаются к наихудшему направлению спуска. Ну и очевидно, что собственные вектора оператора A схлопываются в ноль за одну итерацию. У меня есть подозрение, что в трёхмерии и пространствах большей размерности может получиться что-то более интересное. Надо будет попробоать. Программа:
% File: study_GD_2.m
% dxdy.ru/topic160189.html
% B@R5uk, 2025, April
clc
clearvars
format compact
%format long
format short
num_iter = 3;
% Diagonal bilinear form
A = diag ([1 3]);
func_objective = @(x, A) 0.5 * x' * A * x;
func_gradient = @(x, A) A * x;
% Starting circle and space for data
ppp = 2 * pi * (0 : 0.001 : 1);
num_points = numel (ppp);
xxx = zeros (num_iter, num_points);
yyy = zeros (num_iter, num_points);
xxx (1, :) = cos (ppp);
yyy (1, :) = sin (ppp);
xxx2 = xxx;
yyy2 = yyy;
xxx3 = xxx;
yyy3 = yyy;
% Gradient descent: steepest descent strategy
for k = 2 : num_iter
for l = 1 : num_points
x = [xxx(k - 1, l); yyy(k - 1, l)];
g = func_gradient (x, A);
xx = x - g * g' * g / (g' * A * g);
xxx (k, l) = xx (1);
yyy (k, l) = xx (2);
end
end
% Gradient descent: minimum gradient strategy
for k = 2 : num_iter
for l = 1 : num_points
x = [xxx2(k - 1, l); yyy2(k - 1, l)];
g = func_gradient (x, A);
ag = A * g;
xx = x - g * g' * ag / (ag' * ag);
xxx2 (k, l) = xx (1);
yyy2 (k, l) = xx (2);
end
end
% Gradient descent: fixed step strategy (best step selected)
step = 2 / trace (A);
for k = 2 : num_iter
for l = 1 : num_points
x = [xxx3(k - 1, l); yyy3(k - 1, l)];
g = func_gradient (x, A);
xx = x - step * g;
xxx3 (k, l) = xx (1);
yyy3 (k, l) = xx (2);
end
end
% Objective function levels values
xx = -1 : 0.01 : 1;
zz = zeros (size (xx, 2));
for k = 1 : numel (xx)
for l = 1 : numel (xx)
zz (l, k) = func_objective ([xx(k); xx(l)], A);
end
end
cl = 'wmycg';
% SD graph
subplot (121)
contourf (xx, xx, zz, -1 : 0.1 : 2)
hold on
for k = 1 : num_iter
plot (xxx3 (k, :), yyy3 (k, :), 'LineWidth', 3)
end
for k = 1 : num_iter
% Odd circle image is flipped vertically
plot (xxx (k, :), (-1) ^ (k - 1) * yyy (k, :), 'r', 'LineWidth', 3)
end
for k = 0 : 9
n = 1 + k * 26;
for l = 1 : 2
% Odd circle image is flipped vertically
plot ([xxx(l, n) xxx(l + 1, n)], (-1) ^ l * [-yyy(l, n) yyy(l + 1, n)], cl (mod (k, numel (cl)) + 1))
end
end
n = 251;
l = 1;
% Vertical eigenvector trajectory
plot ([xxx(l, n) xxx(l + 1, n)], (-1) ^ l * [-yyy(l, n) yyy(l + 1, n)], 'w')
hold off
axis equal
xlim ([-1 1])
ylim ([-1 1])
% MG graph
subplot (122)
contourf (xx, xx, zz, -1 : 0.1 : 2)
hold on
for k = 1 : num_iter
plot (xxx3 (k, :), yyy3 (k, :), 'LineWidth', 3)
end
for k = 1 : num_iter
% Odd circle image is flipped vertically
plot (xxx2 (k, :), (-1) ^ (k - 1) * yyy2 (k, :), 'r', 'LineWidth', 3)
end
for k = 0 : 7
n = 1 + k * 32;
for l = 1 : 2
% Odd circle image is flipped vertically
plot ([xxx2(l, n) xxx2(l + 1, n)], (-1) ^ l * [-yyy2(l, n) yyy2(l + 1, n)], cl (mod (k, numel (cl)) + 1))
end
end
n = 251;
l = 1;
% Vertical eigenvector trajectory
plot ([xxx2(l, n) xxx2(l + 1, n)], (-1) ^ l * [-yyy2(l, n) yyy2(l + 1, n)], 'w')
hold off
axis equal
xlim ([-1 1])
ylim ([-1 1])
% Possible colour maps:
% hsv gray hot cool bone copper pink flag
colormap (pink)
В программе несколькими постами ранее, я облажался и вместо zz (l, k) = func_objective ... написал zz (k, l) = func_objective ... Из-за этого на картинке в том же посте (и при работе самой программы) линии уровня целевой функции отображены неправильно: они отражены вдоль диагонали первого квадранта. Другими словами, иксы и игреки перепутаны местами. Надеюсь, в этой программе нет опечаток.
|
|



\\g(x)=0\end{cases}$$")
 единственный подход, который гарантированно работает из того, что я знаю — это параметризовать каким-то образом пространство
единственный подход, который гарантированно работает из того, что я знаю — это параметризовать каким-то образом пространство =0$$") и решать безусловную оптимизацию в новых (параметризующих) аргументах. Такой подход плох во многих смыслах. Первое, целевая функция в новой параметризации может потерять свою изящность и простоту, в частности её производные (особенно вторые) могут стать очень тяжело вычисляемыми. Во-вторых, сама параметризация может потребовать тяжёлых с вычислительной точки зрения функций. В-третьих, новая параметризация может иметь "плохие" точки (например полюса сферы, где сферические координаты "вырождаются"), из-за чего задача в процессе решения может стать плохо обусловленной, что сильно замедляет оптимизацию. Ну и в довершение, чем больше размерность задачи, тем (интуитивно) меньше вероятность уткнуться в локальный экстремум (потребуется, чтобы вдоль
и решать безусловную оптимизацию в новых (параметризующих) аргументах. Такой подход плох во многих смыслах. Первое, целевая функция в новой параметризации может потерять свою изящность и простоту, в частности её производные (особенно вторые) могут стать очень тяжело вычисляемыми. Во-вторых, сама параметризация может потребовать тяжёлых с вычислительной точки зрения функций. В-третьих, новая параметризация может иметь "плохие" точки (например полюса сферы, где сферические координаты "вырождаются"), из-за чего задача в процессе решения может стать плохо обусловленной, что сильно замедляет оптимизацию. Ну и в довершение, чем больше размерность задачи, тем (интуитивно) меньше вероятность уткнуться в локальный экстремум (потребуется, чтобы вдоль