Хорошо, сообразил, что происходит в градиентном спуске при фиксированном шаге, почему он начинает прыгать при больших значениях шага и когда сходится.
Пусть матрица
A задачи является симметричной и положительно определённой.

Направление, противоположное направлению градиента является направлением спуска c фиксированным шагом
β:


Эта простая квадратичная задача очень хороша здесь в плане удобности анализа, потому что шаг метода в этом случае является линейным преобразованием вектора аппроксимации решения:
x_k=S\bigl(\beta\bigr)x_k$$")
x_0=\bigl(I-\beta A\bigr)^kx_0$$")
Где
S — оператор шага. Поскольку матрица
A симметрична, она имеет спектральное разложение, а поскольку она положительно определена, все её собственные значения строго больше нуля. Пронумеруем индексом 1 элемент с наибольшим значением, а индексом 2 — с наименьшим.

=\bigl(I-\beta A\bigr)^k=\bigl(QQ^T-\beta Q\Lambda_0 Q^T\bigr)^k=Q\bigl(I-\beta\Lambda_0\bigr)^kQ^T=Q\Lambda^k\bigl(\beta\bigr)Q^T$$")
,\qquad\qquad\Lambda\bigl(\beta\bigr)=I-\beta\Lambda_0=\left(\begin{matrix}1-\beta\lambda_1&0&\ldots\\0&1-\beta\lambda_2&\\\vdots&&\ddots\end{matrix}\right)$$")
То есть, переход от начального приближения к приближению на
k-ом шаге заключается в масштабировании системы координат вдоль направлений собственных векторов оператора шага
S (которые совпадают с направлениями оператора
A) на величины, равные
k-ой степени соответствующих собственных чисел оператора
S, выражаемых через собственные числа оператора
A. Это означает, что можно сразу перейти в систему координат, заданную собственными векторами оператора
A, и рассматривать только диагональные матрицы.
В этой задаче можно даже точно определить, когда метод сходится. Для этого нужно, чтобы все собственные значения оператора шага
S были по модулю меньше единицы, тогда их степени будут стремиться к нулю экспоненциально (сходимость первого порядка). С помощью положительного коэффициента
β эти значения линейно выражаются через значения оператора
A, которые все тоже положительны и заключены на отрезке, концы которого заданы его максимальным и минимальным собственными значениями:






Левое неравенство в предпоследней строчке выполнено автоматически, потому что мы рассматриваем положительные величины, а второе будет выполнено для всех
n, если параметр шага
β меньше некоторого критического значения, определяемого только наибольшим собственным значением оператора
A:

Надо заметить, что если положить шаг равным критическому, то одно из собственных значений оператора шага
S будет равно -1, а все остальные будут по модулю меньше 1. Поэтому траектория "спуска" будет стремится к траектории, прыгающей между двумя точками, направления на которые от минимума будут задаваться собственным вектором оператора
A, соответствующим максимальному собственному значению этого оператора. Величина -1, возводимая в чётные и нечётные степени, другими словами. Это в том числе, объясняет почему вообще траектории бывают зигзагом: координаты разложения вектора приближения
x по базису собственных векторов операторов
A и
S будут менять знак, если в операторе шага
S имеются отрицательные собственные значения. Однако, это объяснение верно только для градиентного спуска с фиксированным шагом, при других стратегиях выбора шага причины будут другими.
Можно даже найти параметр шага, соответствующий наискорейшему спуску. Для этого требуется, чтобы все собственные значения оператора шага
S были как можно меньше, потолок при этом определит скорость спуска. Поскольку все собственные значения оператора
A заключены на отрезке с положительными концами, необходимо лишь удовлетворить это требование для концов отрезка, для промежуточных значений это будет выполнено автоматически. Другими словами,
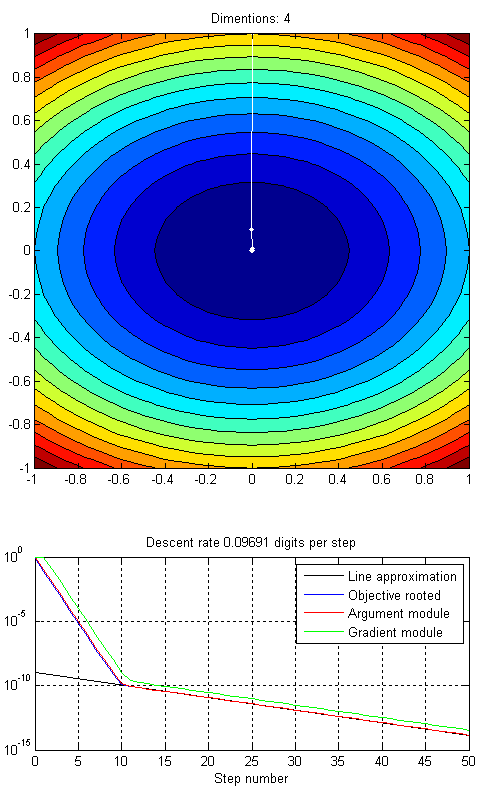
для градиентного спуска размерность задачи не влияет на сходимость.

При этом под правым модулем окажется положительная величина (поскольку вычитаемая мала), а под левым — отрицательная. По этой причине факт того, что траектория представляет зигзаг, является
признаком как близости величины шага к оптимальному, так и к критическому (с оговоркой на фиксированность шага).

Откуда оптимальная величина шага

И скорость сходимости в десятичных знаках на шаг будет равна
=-\log_{10}\left(\frac{\lambda_1-\lambda_2}{\lambda_1+\lambda_2}\right)$$")
В случае, когда собственные значения оператора
A значительно отличаются по порядку, то величина
r будет близка к единице и скорость сходимости в десятичных знаках на шаг окажется
\approx\frac{2}{\ln 10}\cdot\frac{\lambda_2}{\lambda_1}$$")
То есть, очень малой. Интересно, какие вообще методы борьбы с этим существуют?
Если же известно, что задача более-менее хорошо обусловлена — собственные значения оператора
A квадратичной формы вблизи минимума приблизительно одного порядка, — но они неизвестны, то сразу напрашивается следующая стратегия "подкручивания" величины фиксированного шага. Выбираем из каких-то эвристических или эмпирических соображений величину не сильно большую, но и не сильно маленькую. Начинаем градиентный спуск. Каждый раз, когда шаг алгоритма приводит к ухудшению целевой функции отбрасываем результат, умножаем величину шага, на константу меньшую единицы, и пробуем снова. Таким образом придём к величине шага, которая гарантированно меньше критической, но не обязательно близка к оптимальной. Чтобы "нащупать" оптимальную величину, потребуются дополнительные усилия, которые должны в том числе учитывать, что аппроксимация решения на данном шаге может быть вдали от минимума, что означает, целевая функция не будет иметь рассматриваемый выше вид
N+1-мерного эллиптического параболоида. Стоит ещё заметить, что критическая и оптимальная величины шага для случая, когда все собственные числа равны отличаются в 2 раза. Возможно, это тоже можно использовать. Например, если каким-то образом заметить, что зигзаг в траектории решения отсутствует, то можно увеличить величину шага почти в 2 раза.
В случае, если просто заранее задались величиной неизменного шага, то скорость сходимости будет:

Степень сходимости при этом равна 1 (геометрическая прогрессия).
По идее, эта вся инфа должна быть в википедии в первых же абзацах, чтобы сразу врубиться в суть дела и не выводить всё это самостоятельно.


:\mathbb{R}^N\to\mathbb{R},\qquad\qquad f(x)=x^TAx,\qquad\qquad A^T=A$$")
 A \operatorname{diag} (x) x + (x^T B x)^2$$")

