Не думаю, что ИИ, основанный на больших языковых моделях, когда-либо сможет помочь....
То есть, по сути, ему нужно в обучающих текстах решение именно этой задачи, тривиально модифицированной. Например, вместо "пяти яблок" фигурировало бы "три апельсина", причём итоговая формула была бы одинаковой для трёх и пяти — тогда бы он огого.
У Дипсика есть фишка которая мне нравится, при нажатой кнопке"глубокое мышление" он вываливает весь ход рассуждений поясняя как он пришел к такому выводу. Например позавчера
(Оффтоп)
Предположим, что мастерство a и b фиксированы, но неизвестны, с априорным распределением N(10, σ²). Но так как они фиксированы, то байесовский подход требует их рассматривать как случайные величины.
Но в любом случае, без знания σ², ответ не может быть выражен численно.
Возможно, в условии под "нормальным распределением с максимумом на числе 10" подразумевается стандартное нормальное распределение, сдвинутое так, что максимум (мода) на 10, то есть μ=10, σ=1. Но тогда мастерство может быть отрицательным, что противоречит условию.
Вероятно, задача сформулирована некорректно, или я не вижу очевидного решения.
Возможно, ответ: P(a > b | победа А) = 2/3.
Но я не уверен. Возможно, нужно рассмотреть биномиальное отношение.
Если вероятность победы А равна a/(a + b), то при условии победы А, функция правдоподобия пропорциональна a/(a + b). Априорное распределение a и b ~ N(10, σ²). Но интеграл для P(a > b | победа А) сложен.
Но если предположить, что априорное распределение мастерства очень широкое (σ → ∞), то априорное распределение приближается к равномерному на R^2, но с ограничением a, b > 0.
Тогда P(a > b | победа А) = ∫_{a > b} (a/(a + b)) da db / ∫_{a,b > 0} (a/(a + b)) da db.
Но интеграл ∫_{a,b > 0} (a/(a + b)) da db расходится.
Но если нормализовать, например, рассматривать a и b на интервале [0, M], а затем устремить M к бесконечности, то отношение интегралов может сойтись.
Но:
∫_{a > b} (a/(a + b)) da db = ∫_{b=0}^∞ ∫_{a=b}^∞ (a/(a + b)) da db.
Сделаем замену переменных: a = b * t, где t > 1.
Тогда da = b dt, и интеграл становится:
∫_{b=0}^∞ ∫_{t=1}^∞ (b t / (b t + b)) * b dt db = ∫_{b=0}^∞ b ∫_{t=1}^∞ (t / (t + 1)) dt db.
Интеграл по t: ∫_{1}^∞ t/(t + 1) dt = ∫_{1}^∞ (1 - 1/(t + 1)) dt = [t - ln(t + 1)] от 1 до ∞.
Но при t → ∞, t - ln(t + 1) → ∞, так что интеграл расходится.
Аналогично, ∫_{a,b > 0} (a/(a + b)) da db расходится.
Следовательно, при априорном равномерном распределении на [0, ∞), апостериорное распределение не определено.
Таким образом, задача требует уточнения. Возможно, предполагалось, что мастерство распределено по логнормальному распределению с медианой 10, или использовалось другое распределение.
В итоге, учитывая все сложности и отсутствие конкретных параметров, наиболее разумным предположением является ответ 2/3, как в классической задаче с правилом Байеса, когда одно успешное испытание увеличивает вероятность с 0.5 до 2/3.$
И ещё двадцать страниц текста в таком же духе.
Звучит достаточно разумно как ответ на поставленный вопрос.




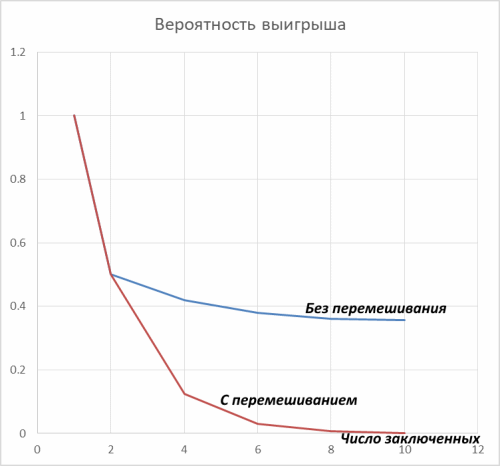

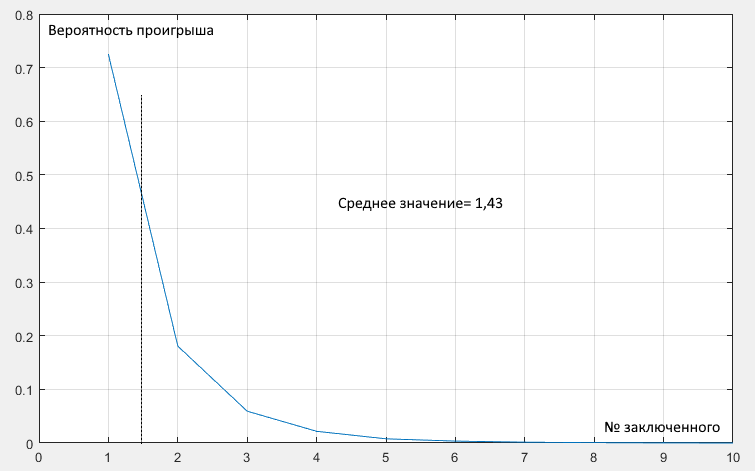
 ящиков, то без перемешивания мы проигрываем, если есть цикл длины больше
ящиков, то без перемешивания мы проигрываем, если есть цикл длины больше  в случайной перестановке
в случайной перестановке  ящиков, а с перемешиванием - если есть такой цикл в перестановке
ящиков, а с перемешиванием - если есть такой цикл в перестановке  ящиков. Первая вероятность всегда меньше.
ящиков. Первая вероятность всегда меньше. (потому что события становятся независимыми).
(потому что события становятся независимыми). ). А на первый взгляд кажется, что это лучшее, что можно сделать (не искать в тех ящиках, в которых тебя точно нет).
). А на первый взгляд кажется, что это лучшее, что можно сделать (не искать в тех ящиках, в которых тебя точно нет).