Мне кажется, пора переходить от моделей "на глазок" к каким-то численным оценкам качества (ну или закругляться, если непонятно, как это сделать; мне непонятно). Ну или как минимум как-то более систематизированно рассматривать модели.
Вообще, у нас каждый участок описывается тремя явными параметрами:

- число зарегистрированных,

- число проголосовавших (для простоты считаем, что число выданных бюллетеней = число "да" + число "нет"; разница небольшая),

- число голосов "за"; можно вместо
брать параметр

. Плюс участок может характеризоваться каким-то числом скрытых параметров. Плюс мы можем дополнительно ввести еще какие-то независимые новые параметры (регион, например) - но это не очень понятно, как делать.
Если скрытых параметров

, то
и

должны быть функциями от
, что даже "на глаз" не очень похоже на правду.
Если скрытых параметров

или больше, то можно сразу всё объяснить ими (просто объявляем

,

), и предсказательная сила такой модели нулевая.
Интересно, когда скрытый параметр один (еще могут быть гиперпараметры модели, одинаковые для всех участков, но пока их мало, мы на них не переобучимся).
Модель Шпилькина: параметры модели

- истинная явка за,

- истинная явка против; скрытый параметр - число добавленных бюллетеней "за"

, предсказание

,

.
Модель
EUgeneUS: параметры модели
- явка среди тех кто за,
- явка среди тех кто против; скрытый параметр -

- доля тех, кто "за" на участке; предсказание:

,
 \cdot r$")
.
Обе модели можно усложнить, сказав, что
и
как-то зависят от
и/или от региона. Как именно предлагается это сделать - я пока не понял.
И получил в чистом виде особенности около 0.5, 1.
Вот эти "особенности" точно надо оценивать количественно. Кроме того, пики же у нас на целых процентах

а не

. И размеры участков лучше брать реальные, а не случайные.
Собственно изначально были пики на графике "явка - число бюллетеней на участках с данной явкой". Количественно - 22.24% бюллетеней на участках с явкой, кратной 5%. Беря реальное число зарегистрированных и случайную явку мне не удалось получить долю бюллетеней на участках с круглой явкой выше 20.2%.


![$[0.4, 1]$](https://dxdy-03.korotkov.co.uk/f/e/0/1/e01de159082455e78340a42b31343dfe82.png "$[0.4, 1]$")
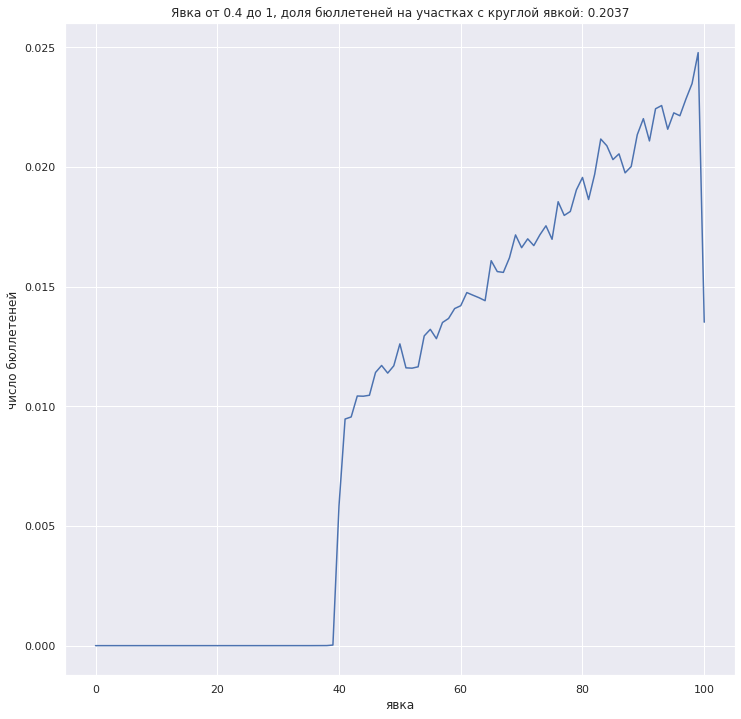



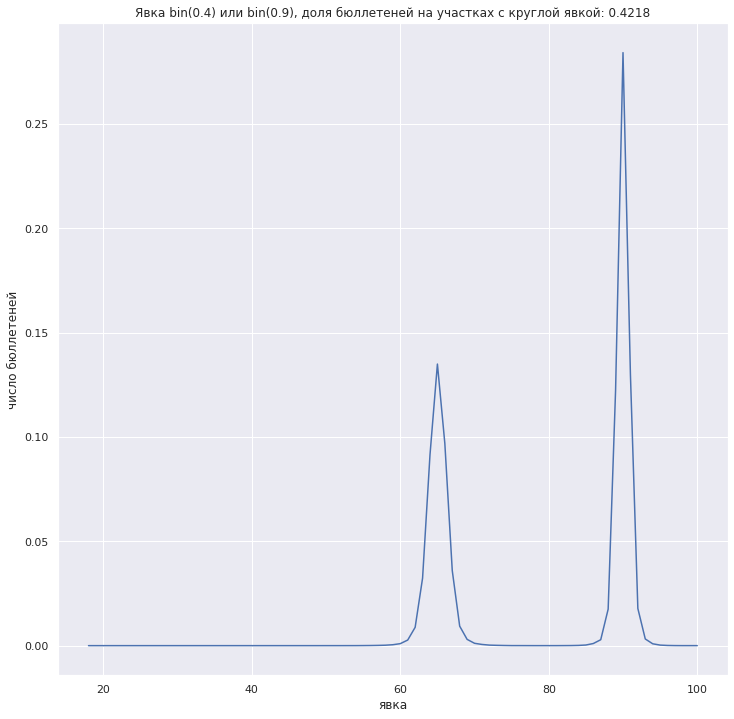








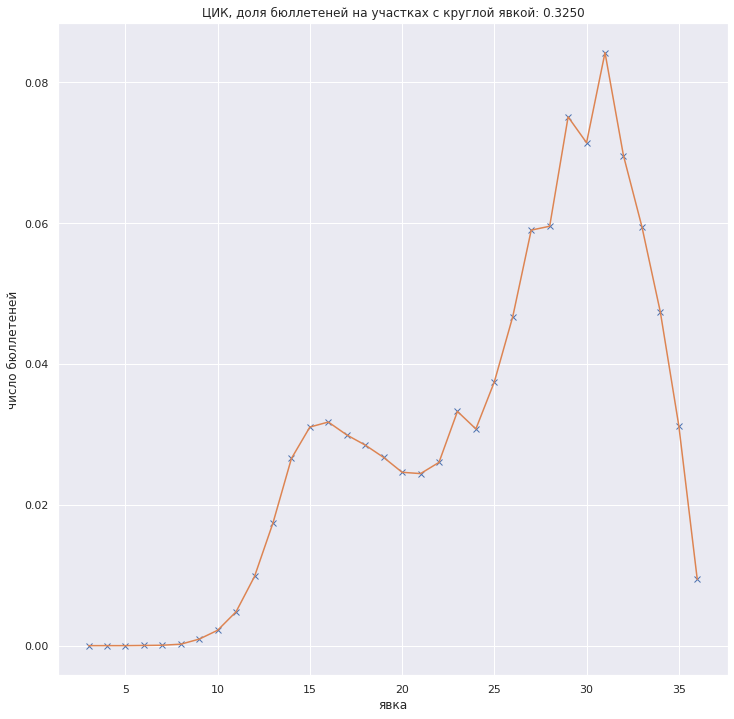


$")




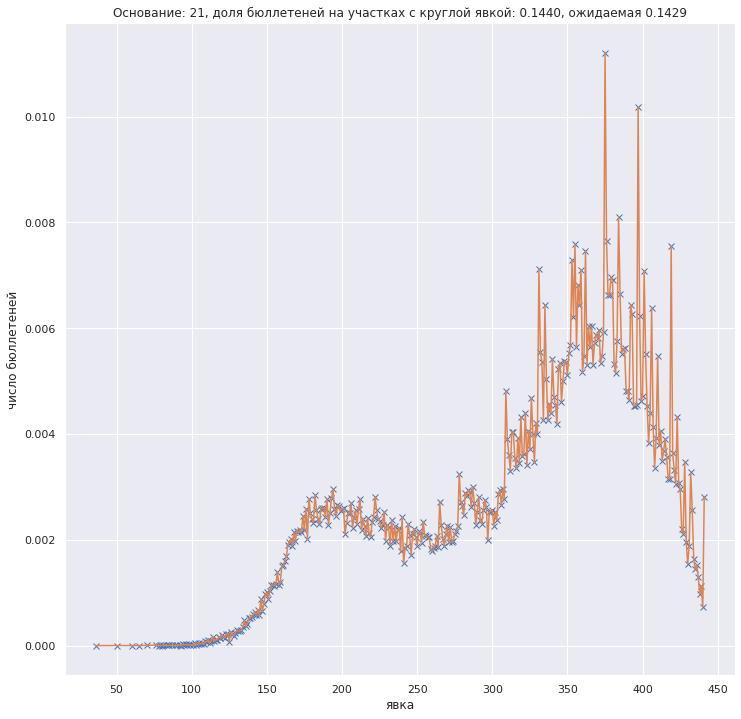

{kind=link}