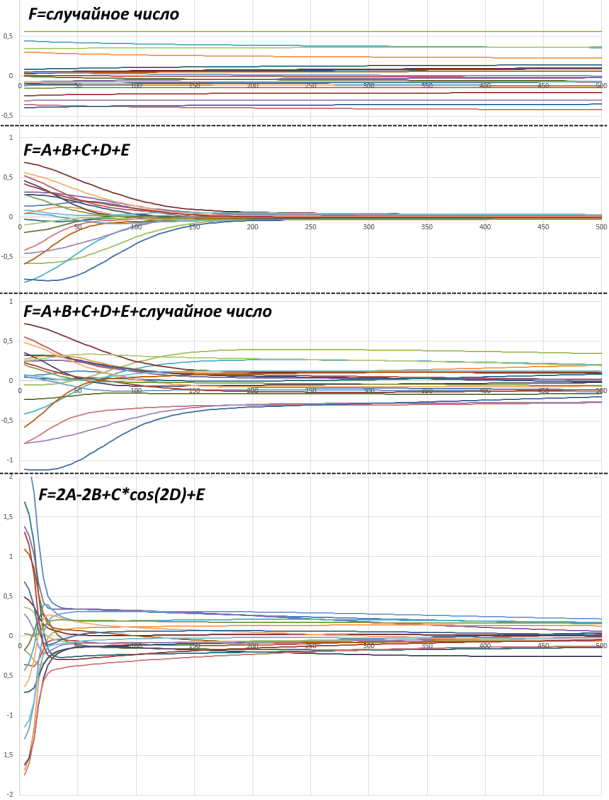
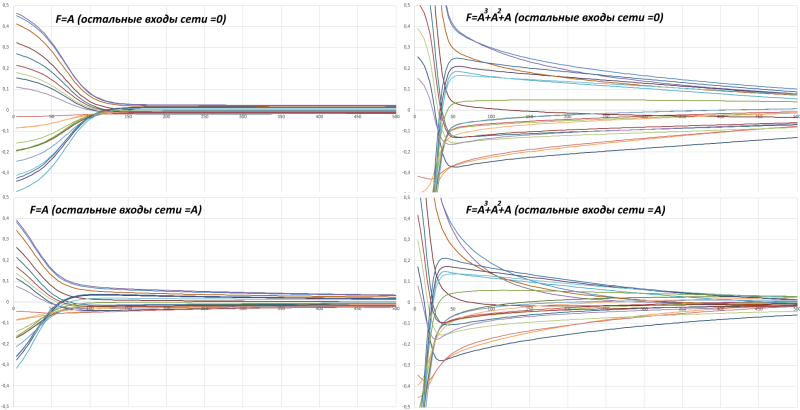
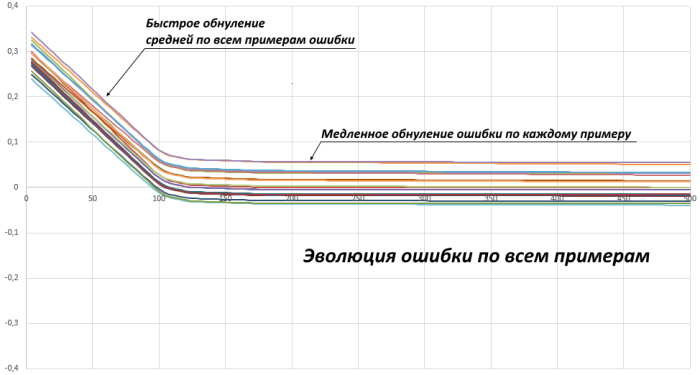
Я разобрался, что у меня было. У меня в наборе всего 20 примеров. При начальной инициализации весов сеть дает некоторую ненулевую среднюю ошибку по всем этим примерам. Часто она вначале ошибается даже просто в одну и ту же сторону на всех примерах. Пока каждый пример требует корректировать веса в одну и ту же сторону, снижение ошибки идет быстро. Но как только средняя по всем примерам ошибка стала равной нулю, дальнейшее снижение ошибки происходит гораздо медленнее. Если отложить эволюцию ошибки сети каждого из 20 примеров в процессе обучения, то получим:
В данном случае тут не квадрат ошибки и не модуль, а просто разность ответа сети и правильного ответа. Меня сбило с толку, что скорость обучения вначале хорошая, но вдруг резко снижается.
Еще раз напишу, как я делал обучение.
Есть пример с правильным ответом

. Сеть дает ответ

. После изменения одного из ее весов

на малый

(постоянный параметр на всем обучении) она на этом же примере дает ответ

.
Абсолютная ошибка ответа
сети есть

Абсолютная ошибка ответа
сети есть

Ошибка изменилась на

Нужно, чтобы подстройка веса приводила к

Тогда нужно подстраивать вес так:

На каждом примере сначала по очереди "дергаются" все веса, затем они все вместе корректируются (на данном примере).
Я заметил, что обучение лучше работает, если вместо
брать

, т.е.

А так обучение в общем работает нормально. Заданную функцию приближает хорошо (при удачном подборе параметров обучения). Пакетное обучение я попробую позже.
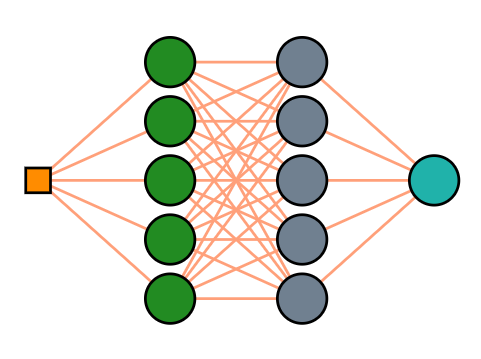
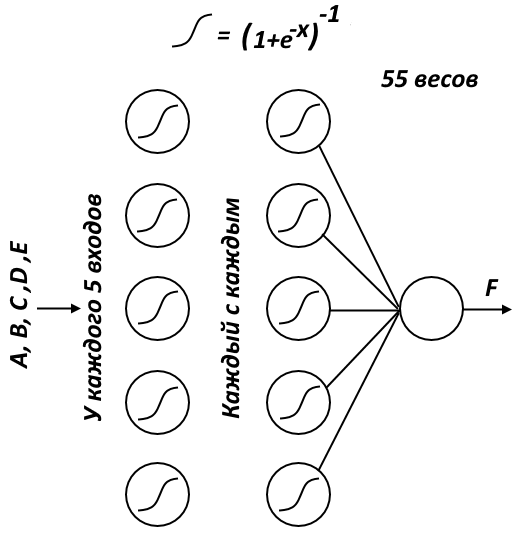
Такой вопрос возникает. У аппроксимируемой функции всего 5 параметров. А у этой сети 55 весовых коэффициентов. Явно избыточно. Но ведь и 5 весов будет явно недостаточно? Как примерно соотносится количество параметров аппроксимируемой функции и число весов сети?





$")