Так, вроде чуть-чуть начинает прояснятся. Пусть имеется матрица
A, в которой число строк меньше числа столбцов и известно, что одна из строк выражается как линейная комбинация остальных (то есть ранг
r матрицы на 1 меньше числа строк):
\in\mathbb{R}^{m\times n},\qquad\qquad r+1=m<n$$")
где
a с индексом — строки матрицы. Находим для неё сингулярное разложение:

}\\&&&\sigma_{m-1}&&\vline&\\0&&&&0&\vline&\end{matrix}\right)$$")
где
I с индексом — это единичная матрица размера, указанного индексом, а 0 с двумя индексами — прямоугольная матрица с нулями. Поскольку в матрице одна строка линейно выражается через другие, последнее её сингулярное значение нулевое:

Перепишем сингулярное разложение в таком виде:

Поскольку все элементы на последней строке матрицы
Σ нулевые, последняя строка матрицы
B тоже будет содержать одни нули (умножение нулевой строки на произвольную матрицу даёт нулевую строку). В последней строке левой части будет стоять некоторая линейная комбинация строк матрицы
A, коэффициентами которой будут элементы последнего столбца матрицы
U. Эта линейная комбинация с необходимостью равна нулевой строке:
^T\left(\begin{matrix}a_1\\a_2\\\ldots\\a_m\end{matrix}\right)=0_{1\times n}$$")
Теперь, ВНИМАНИЕ!!! Самое интересное. Если какой-то из коэффициентов
u с индексами будет нулевым и мы удалим из матрицы
A строку, соответствующую этому коэффициенту, то в результате линейная комбинация потеряет одно нулевое слагаемое, и в ней ничего существенно не изменится: оставшиеся строки матрицы, просуммированные всё с теми же коэффициентами дадут всё ту же нулевую строку. То есть строки новой редуцированной матрицы будут всё так же линейно зависимы, её ранг будет на единицу меньше числа строк, которое будет на единицу меньше числа строк исходной матрицы.
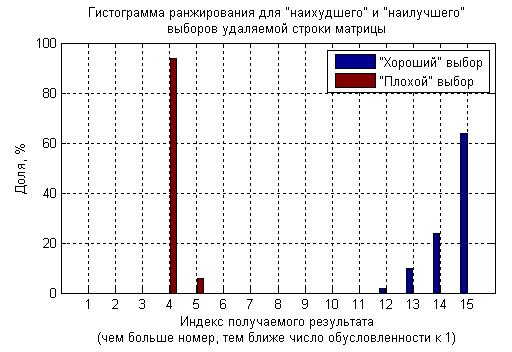
Вывод: удаление строки, соответствующей нулевому коэффициенту нулевой линейной комбинации, приводит к уменьшению ранга матрицы
A (что плохо: потеря информации). То есть, "сильное звено"
svd таки позволяет выявить. Во всяком случае, это происходит в ситуации, когда ровно одна строка выражается через другие. Что происходит в общем случае, я пока не сообразил. Буду благодарен любым наставлениям.
(Оффтоп)
а как Вы его считаете?
-
- >> help cond
- COND Condition number with respect to inversion.
- COND(X) returns the 2-norm condition number (the ratio of the
- largest singular value of X to the smallest). Large condition
- numbers indicate a nearly singular matrix.
-
- COND(X,P) returns the condition number of X in P-norm:
-
- NORM(X,P) * NORM(INV(X),P).
-
- where P = 1, 2, inf, or 'fro'.
-
- Class support for input X:
- float: double, single
-
- See also rcond, condest, condeig, norm, normest.
-
- Reference page in Help browser
- doc cond
-
- >>
И что из этого?
Просто эвристический признак плохой обусловленности матрицы. Как правило, подтверждается вычислениями.
Как можно догадаться что за задачу Вы решаете и откуда берёте свои матрицы, и зачем выкидываете строки?..
Извиняюсь, что непонятно объяснил ситуацию, и поясняю. Пока ничего не решаю, пытаюсь разобраться, как работает сингулярное разложение, какую информацию оно предоставляет о матрице (кроме уже озвученного ранга), можно ли его применить к задаче удаления линейно зависимых строк. Матрицы — любые модельные, на примере демонстрирующие какие-либо свойства. Шума нет никакого. Совсем нет, несмотря на то, что матрицы для тестирования гипотез я создаю случайным образом.
Выбрасывание строк призвано удалить из матрицы излишнюю информацию, которая в ней уже присутствует и без удаляемых строк. Хотелось бы сделать это таким образом, чтобы число обусловленности результирующей матрицы было по-лучше (ближе к 1).


=\theta_k\sigma_k\lbig(A),\qquad\qquad 1\le k\le\min(m,\;n)$$")
\sigma_m\lbig(Y)\le\theta_k\le\sigma_1\lbig(X)\sigma_1\lbig(Y)$$")


$$")