Цитата:
1) Что бросилось в глаза неправильные углы. По идеи они должны быть на 45 градусов повернуты.
Вы имеете ввиду на изображении?
Цитата:
2) Вроде как вектора должны располагаться в столбцах, а вы читаете по строкам.
Хочу уточнить этот момемент.
Допуститм у нас есть такое изображение: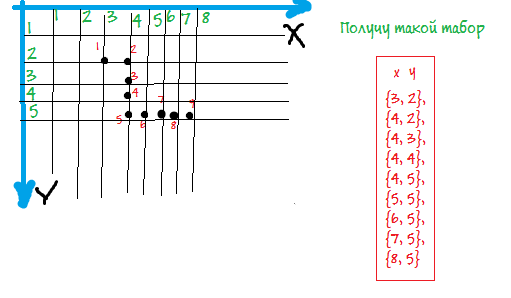 Данные формируются иммено так? Слобец пар из координат? При это не важнен порядок добавления этих точеку в столбец?
Данные формируются иммено так? Слобец пар из координат? При это не важнен порядок добавления этих точеку в столбец?
Я думал так, что если у меня столбец пар {x, y}. То и на выходе я получаю столбец из двух пар {x1,y1}, {x2, y2}. Которые определяют координаты главных компонент. Или не так?
Из такого столбца я получаю вот такие собственные числа и вектора, как мне их интерпритировать?
Код:
double[][] U = {
{3, 2},
{4, 2},
{4, 3},
{4, 4},
{4, 5},
{5, 5},
{6, 5},
{7, 5},
{8, 5}
};
System.out.println("Origin matrix");
Matrix m = new Matrix(U);
m.print(5, 2);
System.out.println("Covariance matrix");
Matrix cov = CovarianceMatrix.getCovarianceMatrix(m.getArray());
cov.print(5, 2);
EigenvalueDecomposition e = cov.eig();
System.out.println("Eigen vectors");
Matrix eigenVectors = e.getV();
eigenVectors.print(5, 2);
System.out.println("Eigen values");
Matrix eigenValues = e.getD();
eigenValues.print(5, 2);
Origin matrix
3.00 2.00
4.00 2.00
4.00 3.00
4.00 4.00
4.00 5.00
5.00 5.00
6.00 5.00
7.00 5.00
8.00 5.00
Covariance matrix
2.75 1.50
1.50 1.75
Eigen vectors
0.58 0.81
-0.81 0.58
Eigen values
0.67 0.00
0.00 3.83
Где здесь координаты первой главной компоненты, а где второй?Цитата:
3) Задайте длину векторов как собственные числа матрицы. И сверху ещё эллипс лучше построить для наглядности.
Это для визуализации только нужно, так? Или от этого зависит куда будут вектора направлены?Цитата:
4) Перескок углов это неустойчивость. Нормально это или нет надо разбираться. Надо смотреть что у вас с ковариационной матрицей и что с собственными числами. Вектора обычно сортируют по собственным числам. А числа по величине.
Тестировал работу на примере вот от сюда:http://neuron-ai.tuke.sk/hudecm/science/9/9.html
На матрице, что у них, получаю:
Origin matrix
2.00 4.00 5.00 5.00 3.00 2.00
2.00 3.00 4.00 5.00 4.00 3.00
Covariance matrix
0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.50 0.50 0.00 -0.50 -0.50
0.00 0.50 0.50 0.00 -0.50 -0.50
0.00 0.00 0.00 0.00 0.00 0.00
0.00 -0.50 -0.50 0.00 0.50 0.50
0.00 -0.50 -0.50 0.00 0.50 0.50
Eigen vectors
-0.00 0.00 0.00 0.00 1.00 0.00
-0.29 0.79 -0.21 0.00 0.00 -0.50
-0.29 -0.21 0.79 0.00 0.00 -0.50
-0.00 0.00 0.00 1.00 0.00 0.00
0.29 0.58 0.58 0.00 0.00 0.50
-0.87 0.00 0.00 0.00 0.00 0.50
Eigen values
-0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 2.00
Если ее транспонировать, практически то что у них(только собственные вектора отличаются):
Origin matrix
2.00 2.00
4.00 3.00
5.00 4.00
5.00 5.00
3.00 4.00
2.00 3.00
Covariance matrix
1.90 1.10
1.10 1.10
Eigen vectors
0.57 0.82
-0.82 0.57
Eigen values
0.33 0.00
0.00 2.67
Почем так разняться результаты?Цитата:
5) Как я уже писал от жеста зависит результат. В одних случаях собственные числа будут близкими в других нет. Если числа близкие то чехорда с векторами может наблюдаться из-за случайных помех.
Понял. Нужно брать хорошо различимые жесты.З.Ы. Скажите пожалуйста. Если использовать эвклидово расстояние, то примерный алгоритм такой:
1. в базе будут храниться изображения жестов(различной ориентации: сверху, слева, справа, снизу)
2. с каждым из изображений я делаю то же что раньше.
2.1 Предвариетельная обработка(фильтрация, выделение руки)
2.2 Канни
2.3 Получаю собственные вектора и значения.
3. На вход подается неизвестное изображение.
4. Для него выполняются шаги 2.1-2.3
Вопрос: между чем ищется эвклидово расстояние(между значения?). То индус, код которого я пытаюсь понять. Предварительно изображения из базы еще и уменьшал до размеров 20х20. Это оправдано?
Могу ли я добавить пунск 2.4 - "уменьшение размеров"
З.Ы.Ы Спасибо большое что помогаете. Без Вас мне был бы каюк.











 И собственно проверяем насколько каждый эталон похож на шаблон.
И собственно проверяем насколько каждый эталон похож на шаблон.

