Это любопытно, хотя на исследование пока что не тянет. Пока что сделана только некоторая техническая работа. Однако задача определения авторства вполне содержательна, так что здесь есть над чем поработать.
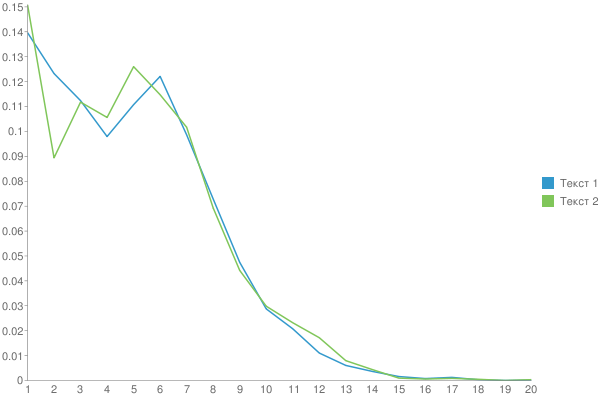
Во-первых, нужно разработать критерий сравнения двух графиков. Это можно делать либо непараметрическим способом, сравнивая непосредственно сами графики, либо же аппроксимировать распределение некоторым параметрическим, и затем сравнивать параметры. Можно попробовать, например, гамма-распределение. У него два параметра, поэтому его будет удобно изобразить на плоскости в виде точки, и затем посмотреть, какие получатся кластеры из таких точек для разных авторов. Интересно, насколько они будут компактны, а также отделены друг от друга.
Интересно посмотреть, получится ли по данному критерию достаточно уверенно определить авторство произведения. (Разумеется, чтобы результаты были честными, нужно обучать данную систему на одних произведениях, а тестировать - на других). Если получится определять авторство, тогда еще интересно посмотреть, как зависит точность от длины предложенного фрагмента текста. Насколько большой кусок нужно взять, чтобы уверенно определить.
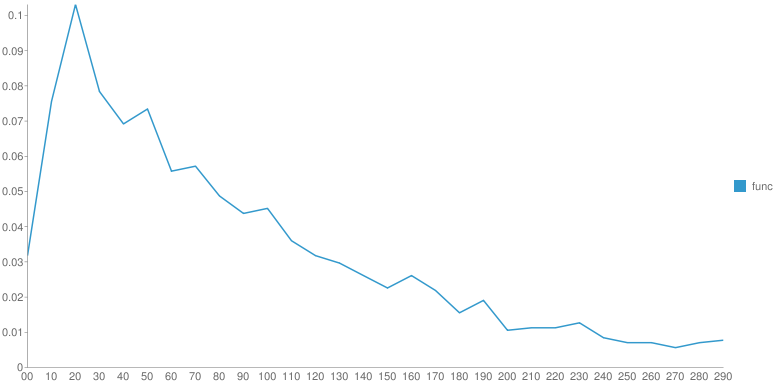
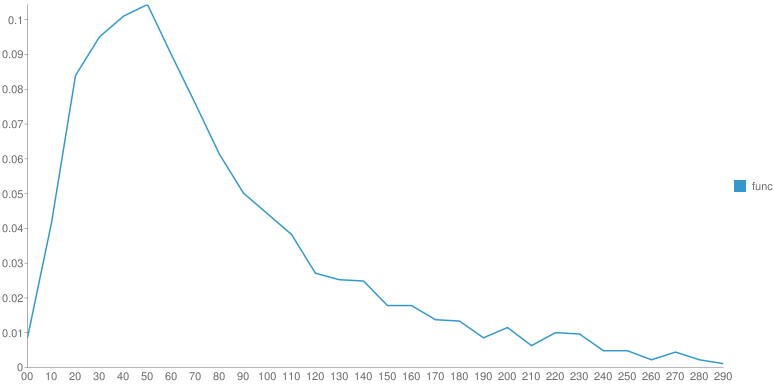
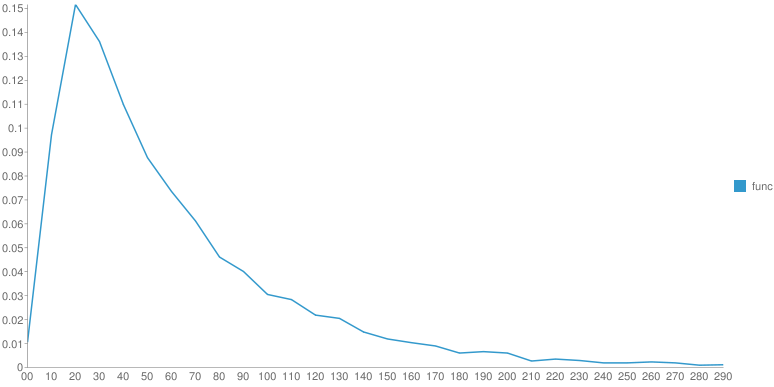
Интересно, насколько устойчиво данное распределение для разных фрагментов одного произведения.
Интересно, меняется ли распределение в зависимости от времени написания (т.е. сравнить ранние и поздние произведения одного автора).
Кроме того, современных авторов массовых произведений, вроде Донцовой, часто обвиняют в использовании труда "литературных негров". Можно было бы попробовать это проверить, используя данный критерий.
Практически все эти вопросы у меня тоже возникают :)
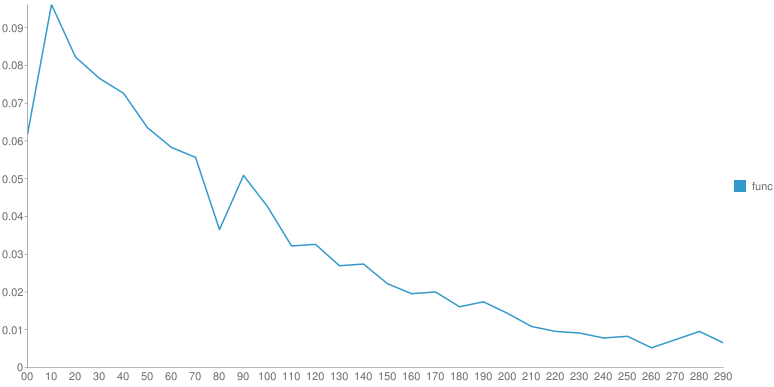
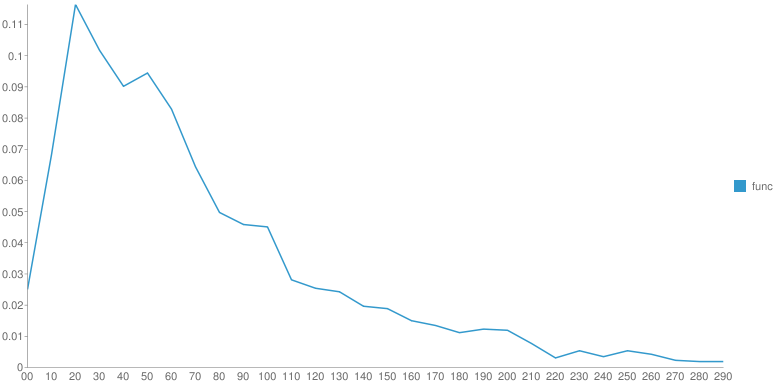
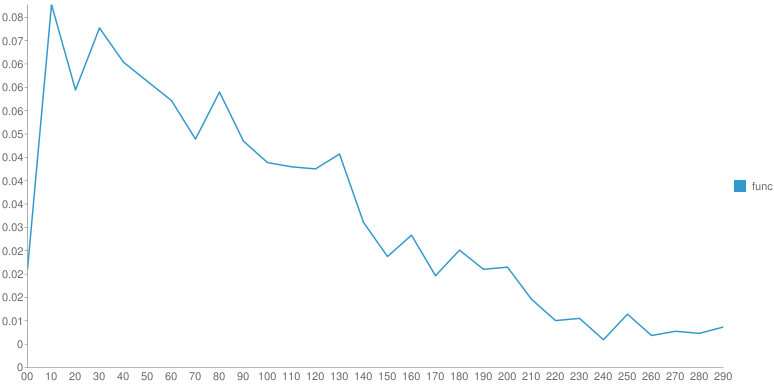
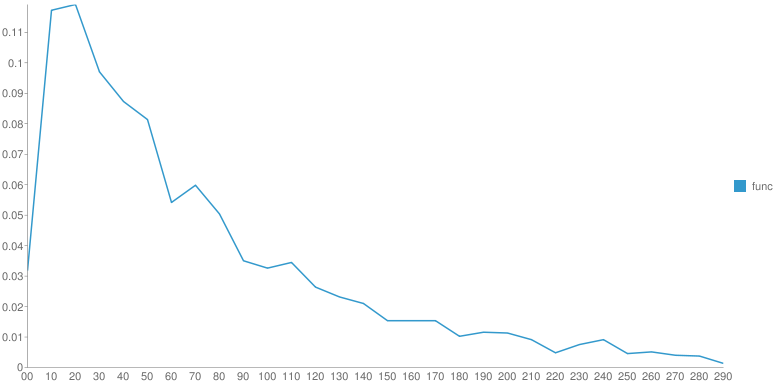
От произведения к произведению одного автора распределение меняется. Но ключевой момент - это гладкость функции после основного максимума. У Шиловой - практически нет рывков, монотонное убывание, у Чехова - самое "растянутое" распределение со множеством локальных максимумов. Вдруг, эти вот локальные максимумы - это и есть проявление авторского стиля? Если взять кучу текста с форумов не будет ли распределение уныло гладким?
Вообще (по секрету) мне интересно, какое распределение будет у автоматически сгенерированного текста (см. дорвеи). Насколько оно будет отличаться от распределения живого человека? Может это является одним из критериев, по которому Google и Яндекс определяют и банят дорвеи?