26/05/12
1918
приходит весна?
|
Последний раз редактировалось B@R5uk 08.05.2025, 12:07, всего редактировалось 1 раз.
Переформулировал в коде программы проверку видимости точек через рассмотренный в соседней теме формализм конечно порождённых конусов (я подозревал, что это может пригодится, но не сразу сообразил как). Теперь для каждой точки одной части множества строится базис из векторов направлений на точки "заграждающего" отрезка. Эти два вектора порождают конус (в плоскости им будет просто угол), а все координаты в этом базисе у точки, находящейся внутри угла-конуса будут положительные. Это значительно понятнее, чем манипуляции с проверками "лежат ли две специально выбранные точки по одинаковые стороны от прямых, содержащих стороны луча", как это сделано в коде выше. Файл test_contact_graph_2.m:
% dxdy.ru/topic160335.html
% B@R5uk, 2025, May
clc
clearvars
format compact
%format long
format short
% Число точек
num_points = 10;
% Минимально допустимое расстояние между точками
thresh_dist = 0.02;
% Порог отсечки на число попыток добавления очередной точки
thresh_area = 100;
% Функция поворота двумерного вектора на 90 градусов против часовой стрелки
func_rot90 = @(v) v ([2 1]) .* [-1 1];
% Функция дробной части числа
func_frac = @(x) x - floor (x);
% Задание конфигурации точек
switch 1
case 1
% Равномерное заполнение квадрата
coords = test_contact_graph_pgen (num_points, thresh_dist, thresh_area);
num_points = size (coords, 1);
case 2
% Сегмент кольца (1/4) и равномерное заполнение угла
coords = test_contact_graph_pgen (floor (0.8 * num_points), thresh_dist, thresh_area);
coords = (0.6 + (sqrt (2) - 0.6) * coords (:, 1)) * [1 1] .* [cos(0.5 * pi * coords (:, 2)) sin(0.5 * pi * coords (:, 2))];
coords = coords (1 > coords (:, 1) & 1 > coords (:, 2), :);
coords = [0.2 * test_contact_graph_pgen(num_points - size (coords, 1), 2 * thresh_dist, thresh_area); coords];
num_points = size (coords, 1);
case 3
% Заполнение через иррациональный псевдогенератор случайности
golden = (sqrt (5) + 1) / 2;
coords = func_frac ((0.5 : num_points)' * golden);
%coords = func_frac ((1 : num_points)' * sqrt (2));
coords = [coords (0.5 : num_points)' / num_points];
end
% Расстояние между точками
dists = repmat (permute (coords, [3, 1, 2]), num_points, 1);
dists = sqrt (sum ((permute (dists, [2, 1, 3]) - dists) .^ 2, 3));
dists = dists + diag (inf (num_points, 1));
% Количество пар точек
num_pairs = num_points * (num_points - 1) / 2;
% Таблица информации о потенциальных рёбрах: индексы вершин, длина, флаг наличия
edges = zeros (num_pairs, 4);
m = 1;
for k = 1 : num_points - 1
for l = k + 1 : num_points
edges (m, :) = [k, l, dists(k, l) 0];
m = m + 1;
end
end
% Сортировка рёбер в порядке возрастания длины
edges = sortrows (edges, 3);
% Таблица связности вершин рёбрами
connectivity = zeros (num_points);
% Таблица видимости пар вершин (на пути нет ребра)
visibility = ones (num_points);
% Количество рёбер
num_edges = 0;
% Количество потенциально невидимых пар
num_vis_count = 0;
% Перебираем все потенциальные рёбра
for k = 1 : num_pairs
% Индексы соединяемых вершин
vrtx_1 = edges (k, 1);
vrtx_2 = edges (k, 2);
% Если между вершинами нет видимости
if 0 == visibility (vrtx_1, vrtx_2)
% Переход к следующему ребру
continue
end
% Увеличиваем счётчик рёбер
num_edges = num_edges + 1;
% Добавляем индексы рёбер в таблицу связности вершин
connectivity (vrtx_1, vrtx_2) = num_edges;
connectivity (vrtx_2, vrtx_1) = num_edges;
% Отмечаем наличие ребра в таблице информации о рёбрах
edges (k, 4) = 1;
% Разбиваем множество точек на две половины, расположенные по разные
% стороны прямой 0, содержащей ребро. Для этого находим вектор,
% ортогональный прямой 0, и считаем скалярное произведение с ним
nvect_0 = func_rot90 (coords (vrtx_2, :) - coords (vrtx_1, :));
tmp = (coords - repmat (coords (vrtx_1, :), num_points, 1)) * nvect_0';
% Индексы точек по разные стороны от прямой 0
indices_left = find (0 > tmp);
indices_rght = find (0 < tmp);
% Исключение идексов точек, задающих прямую, если они оказались в
% списке из-за ограниченности машинной точности
indices_left = indices_left (vrtx_1 ~= indices_left & vrtx_2 ~= indices_left);
indices_rght = indices_rght (vrtx_1 ~= indices_rght & vrtx_2 ~= indices_rght);
% Примитивная оптимизация быстродействия, работающая только в Matlab'е
if numel (indices_left) > numel (indices_rght)
tmp = indices_left;
indices_left = indices_rght;
indices_rght = tmp;
end
% Для каждой точки одной части
for l = 1 : numel (indices_left)
% Рассматриваем конечно порождённый конус (угол) с вершиной в
% точке и векторами направлений на концы добавляемого отрезка
pvect = coords (indices_left (l), :);
base = coords ([vrtx_1 vrtx_2], :) - repmat (pvect, 2, 1);
% Проверка регулярности базиса, то есть, что точка наблюдения
% не лежит на прямой с заграждающим отрезком
[u s v] = svd (base);
% Если это так, то пропускаем точку (по хорошему,
% надо проверить, какие ещё точки лежат на прямой)
if s (end) / s (1) < 2 * eps
continue
end
% Обратная матрица базиса
base_inv = v * s ^ -1 * u';
% Координаты разложения по базису направлений на точки второй части
tmp = (coords (indices_rght, :) - repmat (pvect, numel (indices_rght), 1)) * base_inv;
% Заслоняемые точки имеют только неотрицательные координаты
indices_eclipsed = indices_rght (0 ~= prod (double (0 <= tmp), 2));
% Отмечаем невидимые пары вершин
visibility (indices_eclipsed, indices_left (l)) = 0;
visibility (indices_left (l), indices_eclipsed) = 0;
end
num_vis_count = num_vis_count + numel (indices_left) * numel (indices_rght);
end
% Число точек, число пар точек, число рёбер, трудоёмкость алгоритма
disp ([num_points num_pairs num_edges num_vis_count])
% Множители числа рёбер и трудоёмкости
% Для плоскости число рёбер в пределе бесконечного равномерного
% заполнения плоскости равно 3 на число точек. Трудоёмкость оказывается
% почти пропорциональной кубу числа точек.
disp ([num_edges / num_points num_vis_count / num_points ^ 3])
%subplot (111)
% Отображение точек
plot (coords (:, 1), coords (:, 2), 'k.')
hold on
% Отображение рёбер
for k = 1 : num_pairs
if 1 == edges (k, 4)
plot (coords (edges (k, 1 : 2), 1), coords (edges (k, 1 : 2), 2))
end
end
hold off
% Отображение этикеток к точкам
for k = 1 : num_points
text (0.02 + coords (k, 1), coords (k, 2), num2str (k), 'Color', 'r')
end
axis equal
xlim ([0 1])
ylim ([0 1])
grid on
title (num_points)
Файл test_contact_graph_pgen.m:
% dxdy.ru/topic160335.html
% B@R5uk, 2025, May
function coords = test_contact_graph_pgen (num_points, thresh_dist, thresh_fail)
% Массив для координат точек
coords = zeros (num_points, 2);
% Координаты первой точки
tmp = rand (1, 2);
% Счётчик неудачных добавлений
num_fail = 0;
% Индекс точки
k = 0;
% Если найти новое положение для точки не удалось слишком много раз, то
% скорее всего его не существует, поэтому останавливаемся
while thresh_fail > num_fail
k = k + 1;
% Добавляем новые координаты в список
coords (k, :) = tmp;
% Если желаемое число точек достигнуто, то останавливаемся
if num_points == k
break
end
% Генерируем координаты новой точки до тех пор, пока она не окажется
% на достаточном удалении от всех остальных уже добавленных
while thresh_fail > num_fail
tmp = rand (1, 2);
if thresh_dist < min (sqrt (sum ((coords (1 : k, :) - repmat (tmp, k, 1)) .^ 2, 2)))
num_fail = 0;
break
end
num_fail = num_fail + 1;
end
end
end
(Оффтоп)
Переработал процедуру накидывания случайных точек в квадрат, чтобы она имела более разумный критерий останова, когда точек слишком много для заданного минимального расстояния между ними. Теперь алгоритм стал прозрачным в плане обобщения на более высокие размерности. В трёхмерном пространстве отрезок может быть преграждён участком плоскости, представляющим из себя треугольник, все три стороны которого на очередном шаге оказались отрезками, добавленными в граф (один на текущем шаге, остальные два — ранее). По трём точкам этого треугольника определяется плоскость, делящая всё множество точек на две части (по разные стороны). Для каждой точки одной половины строится конечно порождённый конус на основе векторов, выходящих из этой точки наблюдения в вершины порождающего треугольника. Координаты всех точек второй половины множества раскладываются по базису этого конуса. Только точки, все координаты которых оказались положительными, попадают внутрь конуса и, поэтому, заслоняются треугольником. В четырёхмерном пространстве вместо треугольника надо рассматривать тетраэдр, потому что нужно четыре точки для задания трёхмерной "гиперплоскости". А такая гиперплоскость нужна потому что именно подпространство размерности меньшей на единицу делит всё пространство (и, как следствие, множество точек) на две части. А дальше алгоритм действует как описано выше, только конус теперь порождается четырьмя векторами, а не тремя или двумя, как в трёхмерном или двумерном пространстве, соответственно. Обобщение на размерности выше очевидно. Выше я дал неверную оценку трудоёмкости алгоритма: я посчитал, что раз количество потенциальных рёбер имеет порядок квадрата точек (точнее, равно количеству пар точек), то и в конечном графе их количество тоже будет пропорционально квадрату. Эксперимент показывает, что это не так: на самом деле, на плоскости число рёбер пропорционально числу точек с коэффициентом 2...3. Откуда это число берётся и почему это так, станет очевидно, если рассмотреть предельный случай с плоскостью, полностью заполненной равноудалёнными точками. Другими словами, рассмотреть замощение плоскости равносторонними треугольниками, что эквивалентно задаче плотной упаковки кругов. Каждая вершина в этом замощении будет иметь валентность 6 (количество ближайших соседей), а поскольку каждое ребро соединяет 2 вершины, на каждую вершину в среднем придётся по 3 ребра. Отклонение (в меньшую сторону) среднего числа ребер на вершину от этого оптимального числа 3 в случае случайного заполнения квадрата точками можно рассматривать как некоторую меру неравномерности заполнения. В итоге получается, что алгоритм выше имеет кубическую сложность по числу точек, а не 4-й степени, как я предполагал. По аналогии (не уверен, что это верно, но выглядит правдоподобно), количество рёбер на точку в трёхмерном пространстве будет связано с задачей плотной упаковки сфер. Каждая сфера будет иметь по 6 соседей в содержащем её слое и по 3 соседа в двух соседних слоях (вне зависимости от типа упаковки: ГЦК или ГПУ), то есть всего 12 соседей. Это означает, что оптимальным числом для среднего количество рёбер на вершину будет 6. Что будет происходить в четырёхмерном пространстве, а так же в пространствах высшей размерности я без понятия. Предположительно (опять же по аналогии с пространствами размерности 2 и 3) число рёбер будет тоже пропорционально числу вершин графа с неким целым коэффициентом. Известны точные решения для упаковок в пространствах размерности 8 и размерности 24 (решётки E8 и Лича, соответственно), но я не знаю, как из сказанного о них в вики можно получить число ближайших соседей. Если кто разбирается в вопросе и подскажет ответ, буду очень благодарен. В любом случае, трёхмерная реализация алгоритма тоже должна иметь кубическую сложность. Небольшое уменьшение трудоёмкости алгоритма можно достигнуть, если перед проверкой "заслонённости" пары точек во внутреннем цикле добавить проверку того, что между ними уже пропала видимость за счёт ранее добавленного ребра/треугольника/симплекса. Поскольку одно сравнение проще, чем набор умножений, сложений и сравнений, то константа трудоёмкости заметно уменьшится, особенно для пространств большой размерности. Для увеличения эффективности алгоритма не на константу, а на порядки необходимо эксплуатировать тот факт, что пространство в процессе работы разбивается на симплексы, а из каждой точки, окружённой полным набором таких симплексов остальные точки не видны. Например, подход "разделяй и властвуй" будет пользоваться этим при объединении двух подмножеств: видимость будет достигаться только для граничных точек обоих множеств. Однако, главная проблема подхода выше заключается в том, что в отличие от двумерного пространства, при добавлении очередного ребра в пространствах размерности 3 и выше, может появится несколько новых треугольников, тетраэдров и прочих симплексов. Для каждого из них алгоритм требует разбиения множества точек на две части и проверки видимости. Но я подозреваю, что количество этих сиплексов будет расти комбинаторно-экспоненциально от размерности пространства, а их поиск будет связан с существенными вычислительными затратами. Вывод из всего выше сказанного для меня заключается в том, что для пространств более высокой размерности мне нужен другой, более простой алгоритм. Единственное строгое требование на него — это чтобы он в предельном случае равенства всех минимальных расстояний между точками давал граф из рёбер с этой минимальной длиной. Во всех остальных "неоптимальных" случаях он должен вести себя более-менее разумно, выбирая короткие рёбра со всех сторон вокруг каждой точки, но делая это максимально прозрачно и эффективно (что вполне может дать результаты, отличные от результатов алгоритма выше). Вопрос: как это формализовать?
|
|




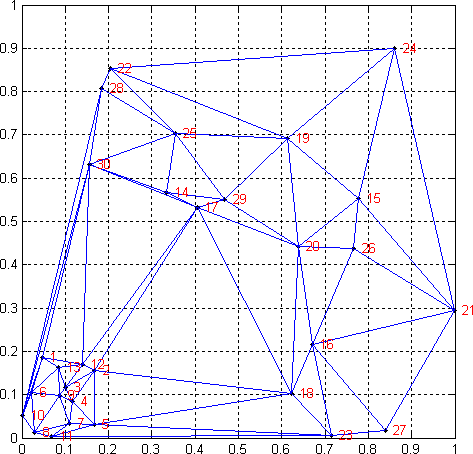
$") от числа точек
от числа точек 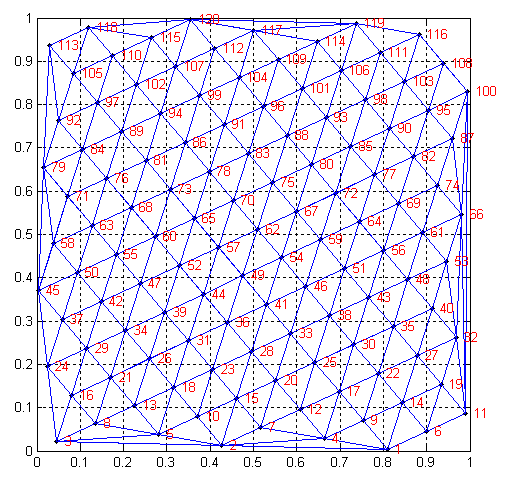
$$")