Правильный подход - заметить, что отклонения измеренных значений от линии имеют равномерное распределение и считать методом максимального правдоподобия для этого распределения. Разумеется, это предполагает, что иной ошибки, кроме ошибки квантования, нет.
Пока рассматриваю утрированную задачу выше. Случайного шума перед квантованием нет. ММП будет означать, что для каждой экспериментальной точки значение модели лежит на некотором отрезке, то есть у нас на каждую экспериментальную точку будет два неравенства (равномерное распределение). Потому что в противном случае (модельное значение выходит за пределы отрезка) функция правдоподобия обратится в ноль.
Другими словами. Вот у меня модель прямой:

для каждой экспериментальной точки

по ММП я получаю пару неравенств:

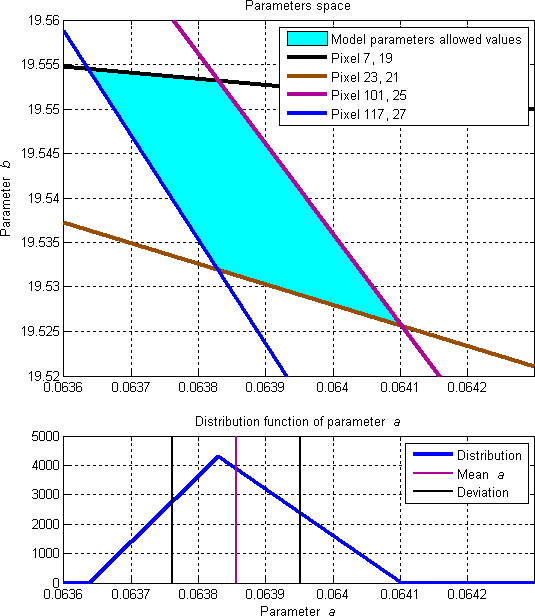
В результате, искомые значения моих коэффициентов прямой — это множество, изображение которого на плоскости a—b является многоугольником, ограниченным парами прямых, соответствующих экспериментальным точкам.
Более, того. Вот у меня есть первая "ступенька" прямой на картинке. Координаты крайних пикселей этой ступеньки (нижний левый угол —

) будут

и

, если я не обсчитался. Из этих экспериментальных точек получаются следующие неравенства на искомые коэффициенты прямой:


Помножим первую систему неравенств на
$")
, а вторую — на

. До тех пор, пока

оба множителя неотрицательны, и знаки в неравенствах сохраняются. Поэтому результаты умножения можно сложить:
a+b-20<1$$")
Получается система неравенств, в которой численный коэффициент перед параметром
a является произвольным числом из отрезка
![$[8,\;22]$](https://dxdy-03.korotkov.co.uk/f/a/9/0/a902d31ab832bce3f7081c268fd0bc5882.png "$[8,\;22]$")
. Этот набор неравенств покрывает в том числе и те, которые соответствуют "экспериментальным точкам"-пикселям из середины рассматриваемой "ступеньки" прямой. Другими словами, в силу линейности модели пиксели внутри ступеньки являются прямым следствием пикселей на концах ступеньки и дополнительной информации о коэффициентах модели не несут.
Евгений Машеров, спасибо большое! Наступило некоторое прояснение. Во всяком случае, ответ на вопрос про информационное наполнение нашёлся.
Задача на студенческую курсовую - генерировать данные и сравнить точности этих подходов.
Кстати, вот интересная же задача. Проблема только алгоритмизовать нахождение коэффициентов по ММП. Пока не представляю, как систематически обрабатывать кучу неравенств. Одно только представление данных (в виде многоугольника) уже что-то нетривиальное по сравнению с МНК.


 Правильно? Потому что, если я возьму дельты по ступенькам линии, то у меня они получатся равными 109 и 7 соответственно, и результат будет
Правильно? Потому что, если я возьму дельты по ступенькам линии, то у меня они получатся равными 109 и 7 соответственно, и результат будет  Какой из них будет точнее? Погрешности я практически из воздуха взял; даже результаты в пределах этих погрешностей не совпадают. Будет ли результат точнее, если я учту, что ступеньки имеют длину 8—15—16—16—15—16—16—15—13 (именно в таком порядке)? Если да, то как?
Какой из них будет точнее? Погрешности я практически из воздуха взял; даже результаты в пределах этих погрешностей не совпадают. Будет ли результат точнее, если я учту, что ступеньки имеют длину 8—15—16—16—15—16—16—15—13 (именно в таком порядке)? Если да, то как? т.к. видно что паттерн повторяется.
т.к. видно что паттерн повторяется. и через
и через  и через
и через  . Все будет подходить, но МНК как раз даст наиболее точный результат.
. Все будет подходить, но МНК как раз даст наиболее точный результат.













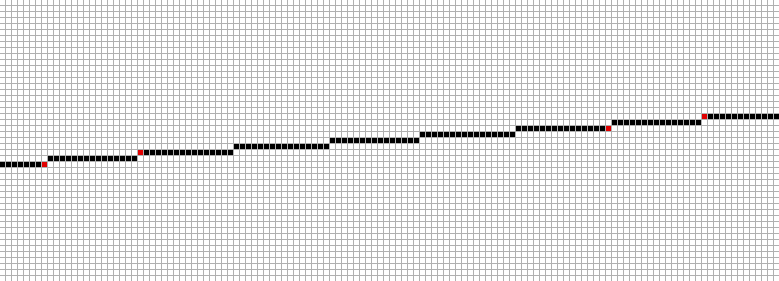
 То есть информация о параметрах модели зашита всего в четырёх пикселях картинки (что, на мой взгляд, очень забавно; думал, будет больше). Ниже я пометил их красным:
То есть информация о параметрах модели зашита всего в четырёх пикселях картинки (что, на мой взгляд, очень забавно; думал, будет больше). Ниже я пометил их красным: