Прежде всего, шахматы игра конкретная, и без счёта вариантов никуда. Поэтому вариант, когда нейросеть выдаёт ход, его и делаем, не рассматривается вообще. Надо считать. На сегодня есть два варианта использования нейросетей в шахматах.
Вариант 1, начал свою историю в программе Giraffe, потом её автор Matthew Lai перешел в DeepMind, где продолжил заниматься этой проблемой. При этом решении используется глубокая конволюционная сетка, которая на входе принимает
$")
входов, которые принимают значения 0 или 1. 64 клетки, 6 типов фигур (король, ферзь, тура, слон, конь, пешка), 2 цвета и одно взятие на проходе. На выходе нейросеть выдаёт два параметра для каждого возможного хода
$")
и

. Сколько ходов считать мне тяжело, их точно меньше чем

(скажем ни одна фигура не може пойти с a1 на b4. И для хода a1-b2 будут отдельные выходы для короля, слона и ферзя. Плюс отдельно рокировки.
Что такое
и
? В принципе по ним можно найти

— аналог оценки позиции, вероятность победы стороны, которой сейчас ход от -1 (100% проигрыш) до +1 (100% выигрыш). И параметр

, который определяет вероятность того, что данных ход лучший. Параметр
используется потом в алгоритме MCTS, а оценка используется в доигрывании (roollout) которое в общем-то обычно останавливается на каком-то шаге (точно не уточнял).
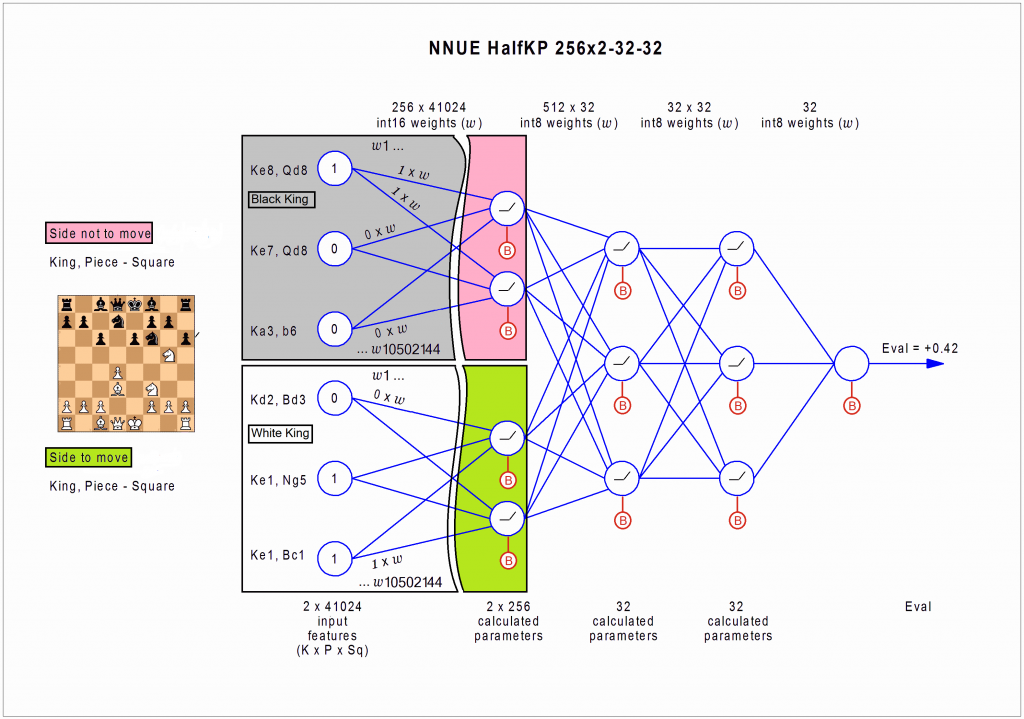
Вариант 2, NNUE сеть для переборного движка Stockish. Изначально идея была в том, чтобы использовать alpha-beta движок Stockfish, содержащий много полезных переборных эвристик, таких как ходы-киллеры, нулевой ход, продления случайные и т. п. для игры в сёги (японский шахматы). Собственно говоря, переборный движок есть, единственная проблема это оценка позиции. Hisayori Noda решил использовать для оценки позиции нейронную сеть, при этом нашёл интересный вариант, когда в процессе операции «сделать ход» некоторыё веса нейронной сети пересчитываются. Получился сильный движок. Более того, идея вернулась в шахматы и появился Stockfish 12, который использует NNUE и играет примерно на 100 пунктов сильнее прошлой версии.
NNUE принимает позицию в достаточно забавном формате. В сёги очень важна позиция короля, на которого часто идут матовые атаки. Поэтому на вход шахматной NNUE приходит
$")
. Первая 64 это число клеток, на которых может располагаться король. А дальше 64 клетки, пять фигур, два цвета + взятие на проходе. На выходу оценка позиции, которая затем используется в Stockfish діижке.
У тут увеличенная
схема NNUE (шире чем 800 пикселей)
На чём обучать? С появлением LeelaZero обучали на всём что только можно, результат оказывался ± одинаковым, но всё же немного сильнее была программа, которая с нуля играла сама с собой. Были варианты обучать на партиях людей, на партиях Stockfish и на партиях против Stockfish. На чём обучается NNUE я не в курсе, но сейчас это очень активно развиваемое направление, и там всё шу́стро меняется.


{kind=link}