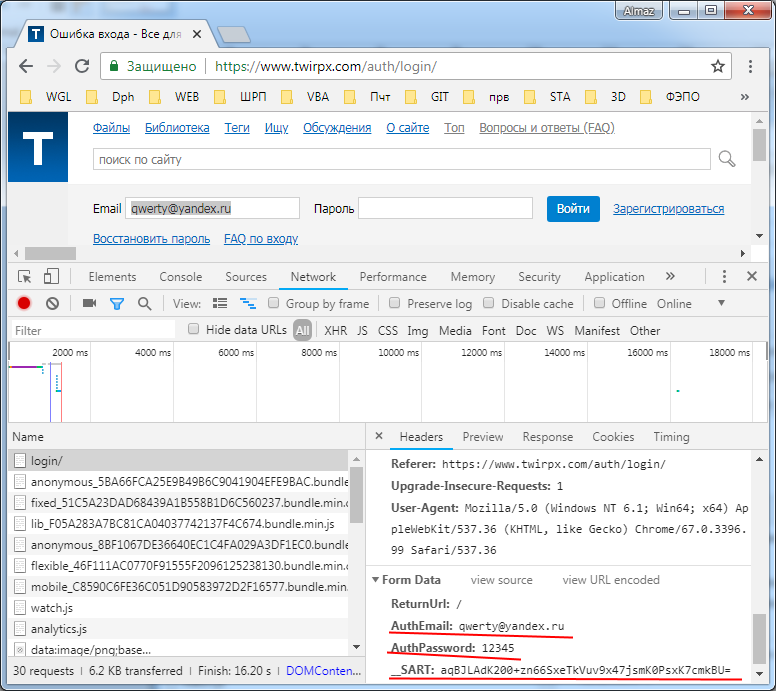
#!/bin/env python3
import requests
import sys
import re
from bs4 import BeautifulSoup
from urllib.parse import urlencode
def filt_func(element):
if element in ['\r','\n','\r\n']:
return False
if element.parent.name in ['style', 'script', '[document]', 'head', 'title']:
return False
elif re.match('<!--.*-->', str(element.encode('utf-8'))):
return False
return True
def main(search_query) :
if not len(search_query):
search_query="кротовые норы"
else:
search_query=search_query[0]
#заголовки начальные
bh={'Host': 'www.twirpx.com','Connection': 'keep-alive','Upgrade-Insecure-Requests':'1','User-Agent': 'Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Encoding':'gzip, deflate, br', 'Accept-Language': 'ru-RU,ru;q=0.8,en-US;q=0.6,en;q=0.4'}
#заголовки для поиска
bh1={'Host':'www.twirpx.com','Connection':'keep-alive','Content-Length':'210','Cache-Control':'max-age=0','Origin':'https://www.twirpx.com','Upgrade-Insecure-Requests':'1','User-Agent': 'Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)','Content-Type':'application/x-www-form-urlencoded','Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Referer':'https://www.twirpx.com/','Accept-Encoding':'gzip,deflate,br','Accept-Language':'ru-RU,ru;q=0.8,en-US;q=0.6,en;q=0.4'}
#новая сессия
s=requests.Session()
s.headers.update(bh)
#получим страницу и распарсим ее
r=s.get('http://www.twirpx.com/')
bs = BeautifulSoup(r.content,'html.parser')
#получим значение поля __SART оно дальше передается в запросе
SART=bs.find("input", {"name":"__SART"})['value']
#тело запроса
sh={'SearchQuery':search_query,'SearchScope':'site','__SART':SART}
#обновим заголовки на новые
s.headers.update(bh1)
r=s.post('https://www.twirpx.com/search/',data=urlencode(sh))
print(r.status_code)
#распарсим ответ
bs = BeautifulSoup(r.content,'html.parser')
#и уберем лишнее
data=bs.findAll(text=True)
lst=list(filter(filt_func, data))
print(('\n-- '.join(str(p) for p in lst)))
#TODO: можно добавить по аналогии и авторизацию на сайте
if __name__=="__main__" :
main(sys.argv[1:])