в первом случае прогнозная точность на новых примерах находится в районе 65%, во втором случае в районе 73%
Очень интересные результаты. Они позволяют предположить, что законы распределения некоторых признаков у Вас сильно асимметричны. В этом случае минимальное значение может оказаться лучше среднего и лучше медианы (уточняю, в Вашем случае значение -999999 следует интерпретировать как минимальное значение по выборке, в контексте древовидных алгоритмов это именно так).
Вот наглядный пример такого распределения:
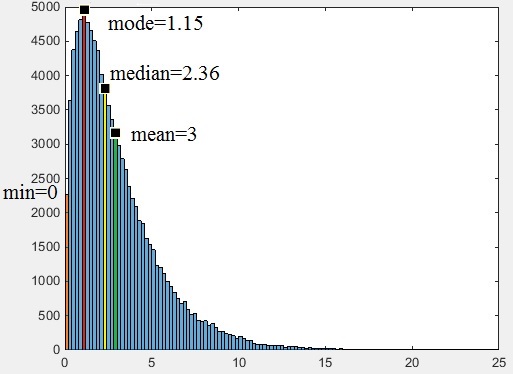
из него видно, что минимальное значение, равное нулю, оказывается даже ближе к наиболее вероятному, коим является мода, чем медиана, а уж тем более - среднеарифметическое. Если признак положительный, а таких у Вас видимо много, то такая ситуация очень вероятна.
Я намекаю на то, что значение -99999 не панацея. Если выяснилось, что среднее и медиана не годятся для использования в качестве наиболее вероятного значения, советую попробовать использовать вместо них значение самой моды. Да, эти значения определяются сложнее, но это один из путей повышения качества алгоритма. Если замена медианы на -99999 приводит к такому улучшению, есть все основания полагать, что замена -99999 на моду так же приведёт к дополнительному улучшению.
И по поводу приведённых цифр, не совсем понятно, они получены с учётом корректировки на отброшенные наблюдения или нет?
И ещё, по поводу отбора признаков. Если это делать на основании кросс-валидации, то результаты самой кросс-валидации, строго говоря, перестают быть валидными. Если этим увлечься, то зайти можно очень далеко (может возникнуть иллюзия создания очень хорошего классификатора, хотя, в действительности всё будет с точностью до наоборот). На мой взгляд, надёжнее и лучше отбирать признаки по внутренним критериям, а кросс-валидацию использовать исключительно для проверки полученных результатов. Ну и чтобы дополнительно обезопасится, советую сразу случайным образом выделить из данных тестовую подвыборку, которая вообще не будет участвовать ни в обучении ни в кросс-валидации и использовать её только 1 раз, при окончательном тестировании модели. Только так можно приобрести хотя бы какую то уверенность в качестве классификатора, ибо риск переобучения в случае древовидных алгоритмов очень велик.


