При практической использовании метода bootstrap возникает вопрос выбора оптимального размера bootstrap псевдовыборки. Оказалось, что этому вопросу уделяется незаслуженно мало внимания, если уделяется вообще. Более - менее внятное рассмотрение данного вопроса удалось найти только здесь:
https://stats.stackexchange.com/questions/96739/what-is-the-632-rule-in-bootstrappingиз за трудностей с переводом, до конца не понял, что здесь имеется в виду, но смутные догадки наталкивают на мысль, что оптимальный размер bootstrap псевдовыборки составляет 63,2% от исходной выборки.
Почему так, непонятно. Так ли оно вообще - полной уверенности нет.
Чтобы хоть как то проверить, я провёл численный эксперимент на парных корреляциях, вовсех случаях N=1000, число репликаций M=1000,
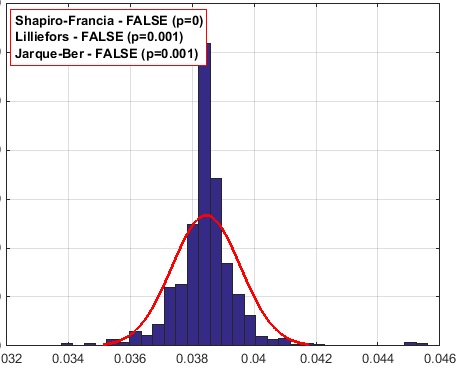
для псевдовыборки k=999
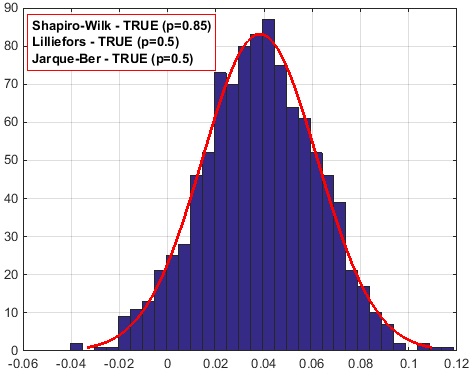
для псевдовыборки k=632
для псевдовыборки k=100
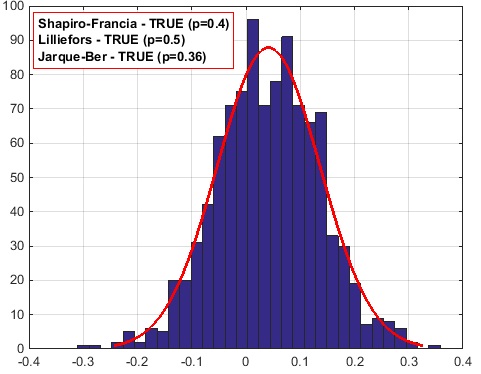
Получается, что для 63,2% результаты самые лучшие, но возможно - это просто случайное совпадение.
Есть ли вообще какие то обоснованные правила выбора размера псевдовыборки? и на что влияет этот размер?
