Оформил генетический алгоритм ...
Hi Skrejet,
I did similar attempts.
Actually this way I composed my lists of best nodes. Starting from sufficiently unbiased seed, remove n primes (in all possible ways), than add n primes (in all possible ways) and store if the product of primes is sufficiently low to fit in a list of predefined number of best nodes. For the graph of size 12, n=3 resulted in enclosed list which n=4 for hours didn't improve even with a single node. For graph of size 13 mutation at depth 4 helped up to some degree, but I didn't finished it completely.
My internal representation of the graph is an ordered set of prime indexes. I did it in this way intentionally to be able to swap safely indexes being sure that always a valid graph is composed. (In addition I took some care to morph the reproduced graph to its canonical form). Again, I blindly did taking all possible combinations of n primes and permuting them in all possible ways (early stopping when obviously some product/node increases too much). This worked with very limited success, as you said, resulting in some "good" graphs which later turned out to be not so good. For the large graphs I hoped that the space becomes more smooth and this could work. Nope. Barriers between the local minima are still too high.
However the exchange of the edges between small subset of nodes worked. Surprisingly, as other mentioned, none of the best graphs was discovered in this way.
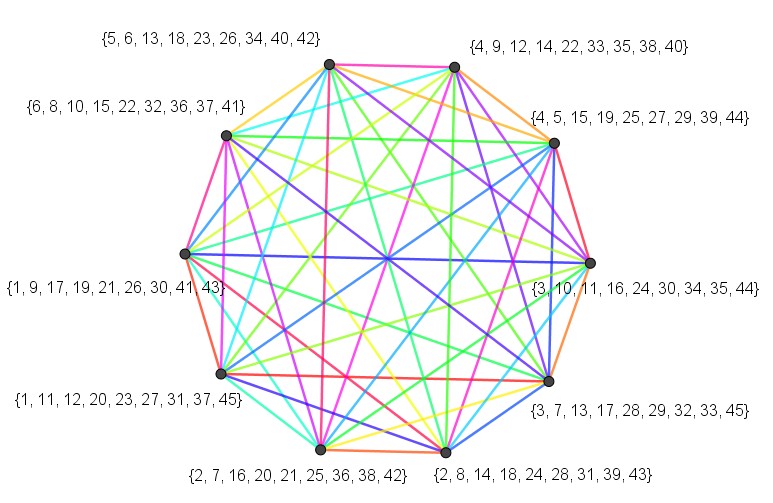
To clarify what I meant by "exchange of edges between nodes". A graph is easy to decompose to 2 pieces by dividing the nodes into 2 groups and cutting the edges between one group and another.
For simplicity let one group consists from nodes (A,B) and the other from the rest nodes (C,D,E,F). We are keeping the edge between A and B as well as all edges between the nodes in the second group. We are cutting 2 edges connecting (A-C) and (B-C) and re-connecting them by exchanging A and B so that the first edge now connects (B-C) and the second (A-C).
The above mutation left nodes (C,D,E,F) unchanged (i.e. the product of the primes connected to them) and changes only nodes A and B. For all the possible such mutations (with also edges to D,E,F involved), one gives minimality for sum(weight(A), weight(B)) and leaves the rest nodes unchanged.
The same is applicable for partitioning the same graph to (A,B,C) union (D,E,F), etc.
I ran code for exhaustive rebuilding of subgraphs of size 3 for thousands of graphs, and up to 4 for the "top" graphs in my cache.
On the other end, I ran code that takes all possible node triplets from a given good graph, and rebuilds graphs (of size 13 to 15) by appending nodes from a list of known good nodes. Again, this resulted in generation of significant amount of good graphs which "surprisingly" were not better than the seed used.
Since these mutations are symmetrical, my explanation is the bias of the seed originating from the previously applied transformations and filtering.


=\begin{pmatrix}\frac {n(n-1)} 2\\n-1\end{pmatrix} $$")
=\frac {(n-k)^kB(n-k)}{B(n)}, \text{ } k = 0...n-1$$")
 is a set of compatible nodes
$$pTotal(n,k)=\prod_{i=0}^{k-1}p(n,i) $$")
 is a set of compatible nodes
$$p(n)= \frac{\left(\frac{n(n-1)}{2}\right)!}{B(n)^{n-1}}$$")
$")
$")
$$E=\sum_{prime \in node} \ln(prime)$$")
} 2} \ln(prime(i)) $")
} \sum\limits_{i=1}^{\frac{n(n-1)} 2}\Biggl((n-1)\ln(prime(i))-\mu\Biggr)^2$$")
\approx \frac 1 2 \exp(\mu)(E-\mu)^2 $$")
$$")
![Number of nodes with energies in the interval $[\mu-\varepsilon,\mu+\varepsilon], \varepsilon\ll1$
$$N(n,\varepsilon)\approx \frac{2 \varepsilon B(n)} {\sqrt{2\pi\sigma^2}} $$](https://dxdy-01.korotkov.co.uk/f/c/4/d/c4d7475a6123202c4ce81be1850adbda82.png "Number of nodes with energies in the interval $[\mu-\varepsilon,\mu+\varepsilon], \varepsilon\ll1$
$$N(n,\varepsilon)\approx \frac{2 \varepsilon B(n)} {\sqrt{2\pi\sigma^2}} $$")
![Expected value for the rawscore for a solution made with $n-1$ nodes in the interval $[\mu-\varepsilon,\mu+\varepsilon], \varepsilon\ll1$ and the last node forced
$$R(n,\varepsilon)\approx \frac 1 3 \exp(\mu)(n-1)\varepsilon^2 $$](https://dxdy-03.korotkov.co.uk/f/e/0/0/e002cea53e39e440eb00250fbf0eb1bc82.png "Expected value for the rawscore for a solution made with $n-1$ nodes in the interval $[\mu-\varepsilon,\mu+\varepsilon], \varepsilon\ll1$ and the last node forced
$$R(n,\varepsilon)\approx \frac 1 3 \exp(\mu)(n-1)\varepsilon^2 $$")